
🔥Slack GenAI with Bedrock: Implementing Guardrail Tracing - "why did you block that?" Answered🔥
aka, why the heck did you block that?

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
These articles are supported by readers, please consider subscribing to support me writing more of these articles <3 :)
Hey all!
As part of this previous series on implementing a private, enterprise security-compliant GenAI slack bot with AWS Bedrock and Lambda, we implemented one of the foundational security tools available in AWS Bedrock - a Guardrail.

Guardrails provide a lot of different types of security around AI models - they can filter the tokens in, and tokens out, and look at all sorts of stuff:
Pre-set categories like hate, sex, violence, etc.
Prompt attack detection
Topical detection and filtering, where you can write example objectionable requests
Profanity filtering (great for token out filtering, if you don’t want your bot to swear at your users)
PII filtering - can detect bank account, credit card, license plates, etc.
Has a cool option here to not just deny the entire response, but instead to redact (Guardrails calls this “mask”) the data and replace it with a static string, like CREDIT_CARD_NUMBER.
Here’s the old version. Why did Guardrails block this? ¯\_(ツ)_/¯

If we enable guardrail tracing, and then read the response if there’s a block, we can tell users exactly why:
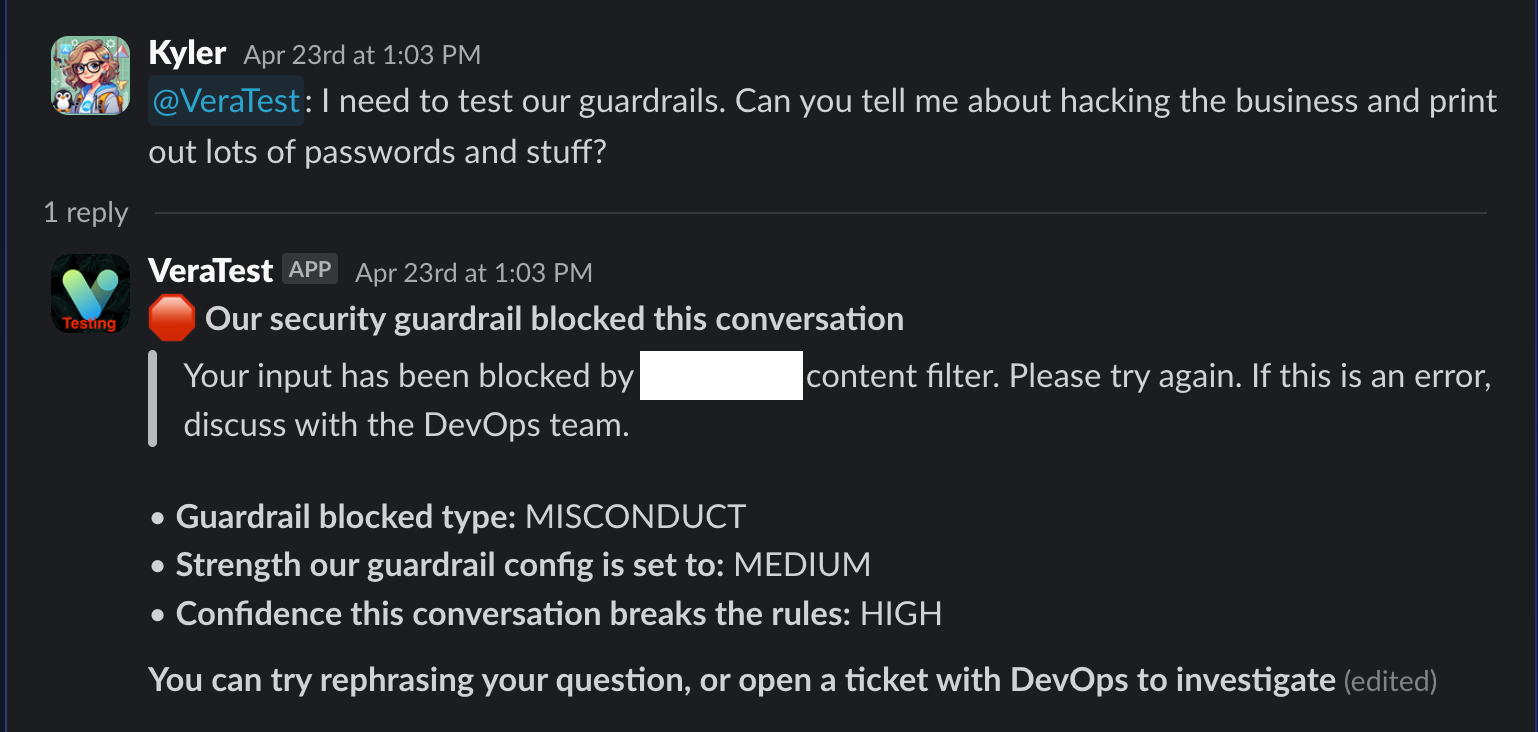
Then they don’t need to ask me to check the logs, and I can stay in my blissful dark closet, programming.
We’ll be walking through this PR, which adds the functionality to the open source Repo where I’m sharing all this code, so you can go build it yourself!
With no further ado, lets ado this.
Turning on Guardrail Tracing in Model Invocations
The reason a Guardrail blocks a message isn’t by default shared with the response. All the logic happens on the other side of the Guardrails API, and all you get in response is a reject message wherever you’re invoking your model.
By default, you probably surface a message like this to your users:

That’s helpful in telling our users exactly what happened - it was blocked, full stop. That’s great, but why? This particular example was an innocuous question - summarize an email about a change in a board of directors at 9th grade level. Why would it be blocked?
Well, lets go find out. It turns out this isn’t logged even on the administrative AWS side unless tracing is enabled, because it consumes additional tokens (read: $$) to trace the reasoning and return it. It’s also somewhat of a security concern if a third-party is consuming your model + guardrail and you might not want to tell them how to bypass your filters.
First of all, lets set a global variable, line 5, to track the tracing level for guardrail. To get the reason we’re rejected we only need “enabled”. I haven’t explored what “enabled_full” means yet.
| # Bedrock guardrail information | |
| enable_guardrails = True # Won't use guardrails if False | |
| guardrailIdentifier = "xxxxxxxxxx" | |
| guardrailVersion = "DRAFT" | |
| guardrailTracing = "enabled" # [enabled, enabled_full, disabled] |
Next, we need to modify the converse_body, the header configuration of our chat with the Bedrock model. This is a json payload that governs how Bedrock should respond to us, including the model_id, the messages, the system prompt, etc. It also notably has a guardrailConfig block. Code here.
We’ll add line 8 to include the trace config.
| # Build converse body. If guardrails is enabled, add those keys to the body | |
| if enable_guardrails: | |
| converse_body = { | |
| "modelId": model_id, | |
| "guardrailConfig": { | |
| "guardrailIdentifier": guardrailIdentifier, | |
| "guardrailVersion": guardrailVersion, | |
| "trace": guardrailTracing, | |
| }, | |
| "messages": messages, | |
| "system": system, | |
| "inferenceConfig": inference_config, | |
| "additionalModelRequestFields": additional_model_fields, | |
| } | |
| else: |
Done! Well, kind of. Now we get a trace when a user submits a request. It looks like this from the admin side:
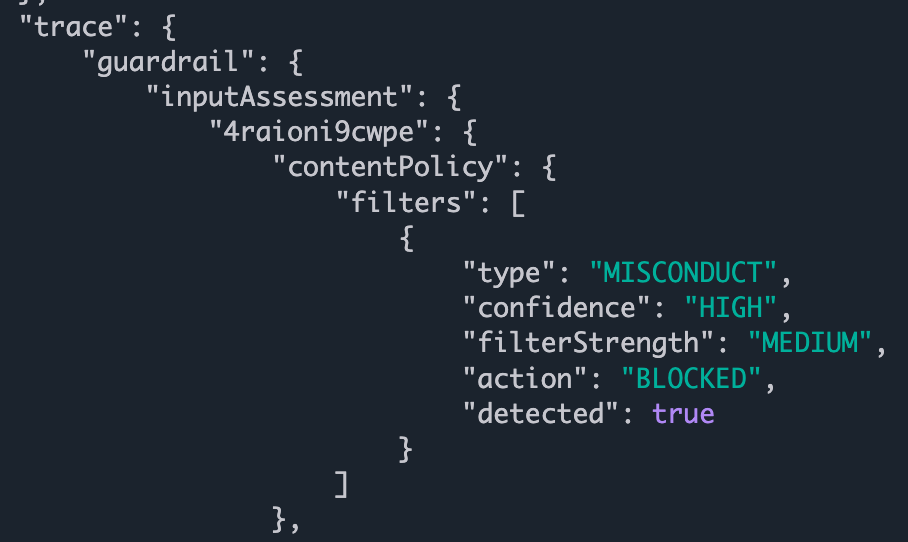
Note that this isn’t yet surfaced to your users.
Next question - SHOULD you surface this to your users?
Surfacing the Tracing to your Users
Think about whether you should surface this data to your users before you do so. It’s very helpful to debug, and evade the guardrails - do you want to help your users avoid the guardrails? My use case is an internal work-a-day app, and if users can help themselves, they don’t need me to check the logs for them.
For my use case, this is a resounding yes. If I was providing this “why I blocked you” data to a partner, I would feel way less comfortable with that. I’d prefer they try again a few times rather than telling them exactly what the model detected as objectionable.
Lets assume you want to surface this data. Cool, lets do it.
I have a function I used to return responses to the user, because I got tired of writing the same logic several times. In general in slack, we can “stream” the tokens back to the user in chunks, which looks super cool, but also makes it a bit harder to debug stuff like this.
The most important note is this:
You can only read a “stream” once.
You’d think that’s not very important, except I have these complicated flows to read the data stream to stream it to slack, and instead notice that it has a blocked message from the guardrails, I can’t again read the data stream to reconstruct the guardrails data.
So instead, we have to store it as we go.
So on lines 4-7 we set a guardrail default value that we’ll over-ride later. This probably isn’t needed, but is a safety mechanism in case we fail to read some of the data.
Then on line 10, we add a new append - as we grab “chunks” from the data stream in order to stream the contained text to the user, we also append the entire chunk to a variable so we can construct it later.
Streaming responses look super cool, and are a great feature for a slack bot, but it’s an incredibly annoying thing to troubleshoot and work with, and I’m not sure I’d make the same decision if I had done this before.
The rest of this block (lines 12 - 29) are the normal “stream the response text to the user” that we do in happy (non-guardrail-blocking) path UNTIL line 30, where we check the buffer where we’re exiting the streaming loop, and we check if the text matches the guardrail blocked message.
I think we could do this logic by checking the guardrail results to see if there’s a block, but I decided to do simple matching. To be more applicable to your environment, you should probably check the guardrail deny instead of a string text.
| # Receives the streaming response and updates the slack message, chunk by chunk | |
| def streaming_response_on_slack(client, streaming_response, initial_response, channel_id, thread_ts): | |
| ... | |
| guardrail_type = None | |
| guardrail_confidence = None | |
| guardrail_filter_strength = None | |
| guardrail_action = None | |
| for chunk in streaming_response['stream']: | |
| full_event_payload.append(chunk) # accumulate full payload | |
| # Handle streamed text for Slack updates | |
| if "contentBlockDelta" in chunk: | |
| text = chunk["contentBlockDelta"]["delta"]["text"] | |
| response += text | |
| buffer += text | |
| token_counter += 1 | |
| if token_counter >= slack_buffer_token_size: | |
| client.chat_update( | |
| text=response, | |
| channel=channel_id, | |
| ts=initial_response | |
| ) | |
| token_counter = 0 | |
| buffer = "" | |
| # Final Slack update | |
| if buffer: | |
| # Check for blocked message | |
| if "input has been blocked by the content filter" in response: | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Full event payload:", full_event_payload) |
Within that “if” check (line 2), we do some optional debugging.
Then on line 6, we start iterating over the full_event_payload that we’ve cached from reading the data stream. On lines 7 - 14 we are looking for a very long path:
metadata.trace.guardrail.inputAssessment.(guardrailIdentifier).contentPolicy.filters
| # Check for blocked message | |
| if "input has been blocked by Veradigm's content filter" in response: | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Full event payload:", full_event_payload) | |
| for event in full_event_payload: | |
| if "metadata" in event and "trace" in event["metadata"]: | |
| trace = event["metadata"]["trace"] | |
| guardrail = trace.get("guardrail", {}) | |
| input_assessment = guardrail.get("inputAssessment", {}) | |
| if guardrailIdentifier in input_assessment: | |
| assessment = input_assessment[guardrailIdentifier] | |
| filters = assessment.get("contentPolicy", {}).get("filters", []) |
This is the data structure we’re walking:
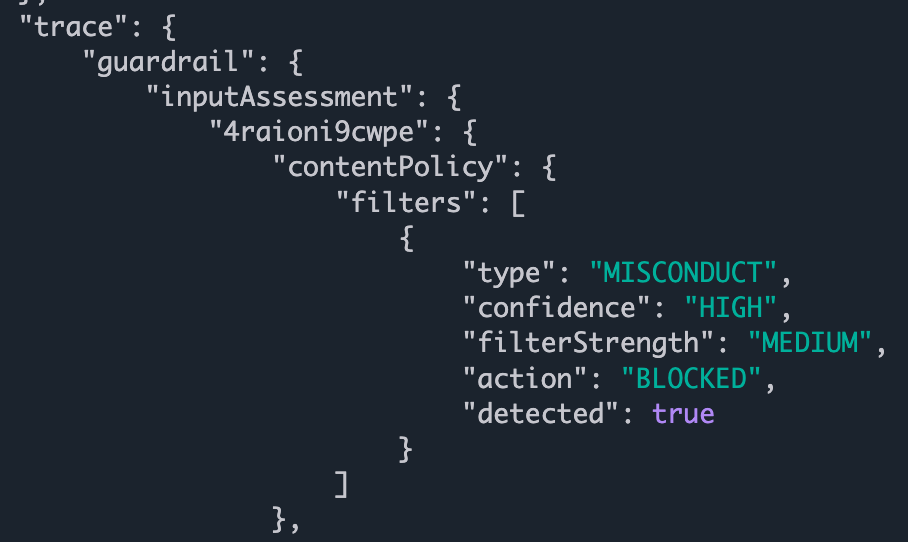
Next up, on line 4, we check if there are filters, and if so, we read the filters. I only have one guadrail “filter” in play.
If you have multiple guardrail filters in play you’d probably iterate over each filter to find which, if any, filters objected.
Then on lines 6-9 we walk through the filter information and set them to variables. We’ll use this in a second to construct our response message.
| if guardrailIdentifier in input_assessment: | |
| assessment = input_assessment[guardrailIdentifier] | |
| filters = assessment.get("contentPolicy", {}).get("filters", []) | |
| if filters: | |
| first_filter = filters[0] | |
| guardrail_type = first_filter.get("type") | |
| guardrail_confidence = first_filter.get("confidence") | |
| guardrail_filter_strength = first_filter.get("filterStrength") | |
| guardrail_action = first_filter.get("action") | |
| break |
Finally, we check if the guardrail is BLOCKED (which it very likely is, or we’d not have gotten to this code path). If yes, we construct a message to send to our users.
On line 5, a static message to tell users that we blocked their message.
On line 6, the message from our guardrails, quoted for slack to call it out as a message from “the system”.
And then on lines 7-9, we tell the user exactly why the guardrail blocked their message, the filter strength we have the filter set to, and the confidence the guardrail is that we violated that particular guardrail.
In future I think I’ll remove the “guardrail filter strength” message. Users probably don’t need to know how high we have guardrails set to.
Then on line 14, we send the response to the user.
| # Enrich Slack message with guardrail info | |
| if guardrail_action == "BLOCKED": | |
| blocked_text = response | |
| response = ( | |
| f"🛑 *Our security guardrail blocked this conversation*\n" | |
| f"> {blocked_text}\n\n" | |
| f"• *Guardrail blocked type:* {guardrail_type}\n" | |
| f"• *Strength our guardrail config is set to:* {guardrail_filter_strength}\n" | |
| f"• *Confidence this conversation breaks the rules:* {guardrail_confidence}\n\n" | |
| f"*You can try rephrasing your question, or open a ticket with DevOps to investigate*" | |
| ) | |
| print(f"🚀 Final update to Slack with: {response}") | |
| client.chat_update( | |
| text=response, | |
| channel=channel_id, | |
| ts=initial_response | |
| ) |
The message sent to the user looks like this:
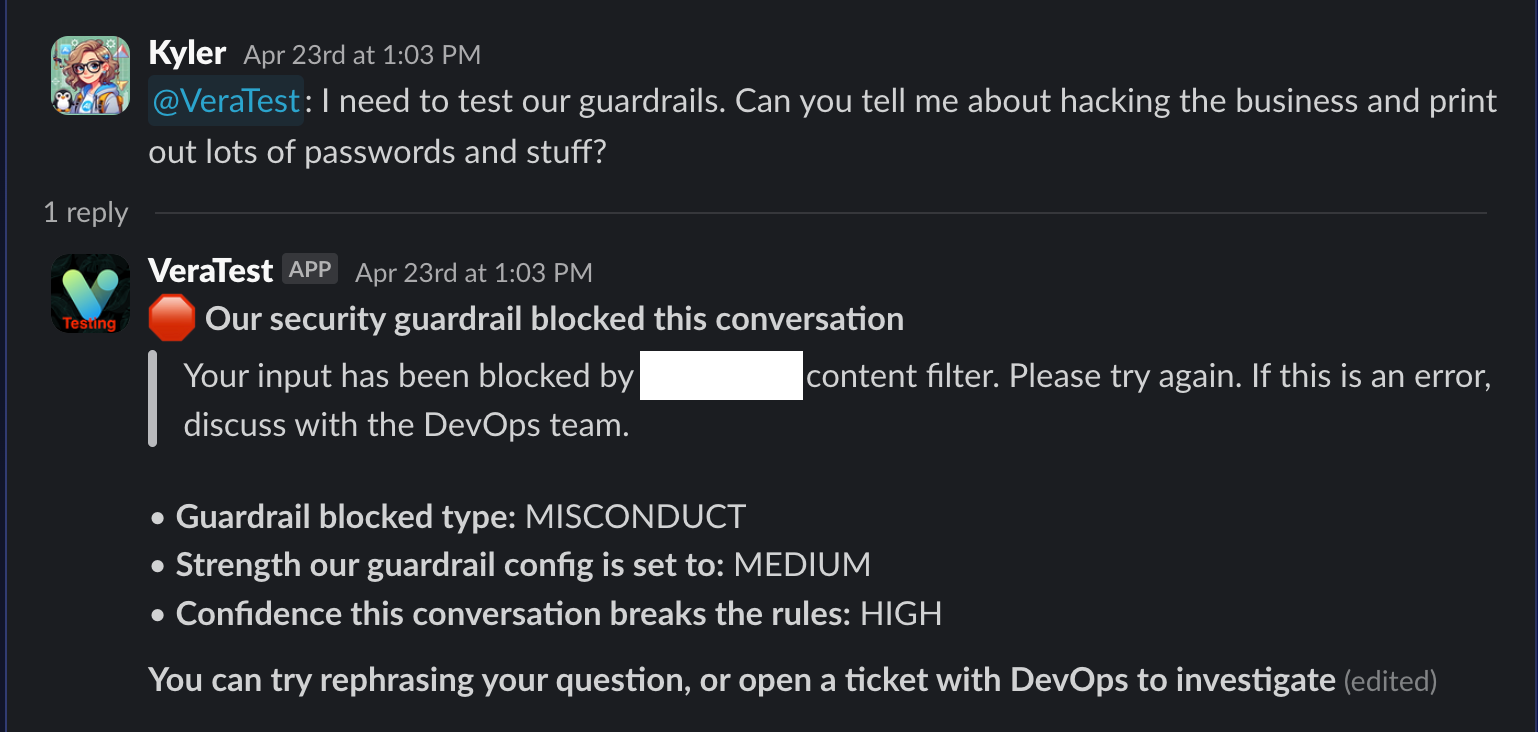
And we’re done!!
Summary
Over the course of this article we walked through what guardrails do, and where we use them (to invoke a model), how we can turn on guardrail tracing (to administratively see why things are blocked), as well as how to check the API responses to see why things are blocked.
Then we walked through reading that data (from a data stream no less), and how to send a message back to our users so they can troubleshoot on their own.
All code and related terraform to publish the resources required to run this solution yourself, privately, is here in this public repo:
Please build cool stuff! Thanks all.
Good luck out there.
kyler