
🔥Building a Slack Bot with AI Capabilities - Part 9, Reducing Cost and Complexity with a Lambda Receiver Pattern🔥
aka, respond "received" and then die

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
These articles are supported by readers, please consider subscribing to support me writing more of these articles <3 :)
This article is part of a series of articles, because 1 article would be absolutely massive.
Part 1: Covers how to build a slack bot in websocket mode and connect to it with python
Part 4: How to convert your local script to an event-driven serverless, cloud-based app in AWS Lambda
Part 7: Streaming token responses from AWS Bedrock to your AI Slack bot using converse_stream()
Part 8: ReRanking knowledge base responses to improve AI model response efficacy
Part 9 (this article!): Adding a Lambda Receiver tier to reduce cost and improve Slack response time
Hey all!
Welcome to the final entry into this comprehensive series of how to build and iteratively improve an GenAI-powered slack bot with Lambda and Bedrock. This series has been an incredible journey, and I’m trying to close it out as well as I can by establishing a proper receiver.
First, lets go over what we talked about. First, we established how to build a Slack Bot, and permissions in Slack, and how to trigger it. Then we talked about what a slack webhook payload looks like, and how to read it and walk over a slack thread to construct a conversation. We do that with lambda, then we convert it all to the .converse() standard API at AWS that fronts all of their models.
We put it all in lambda, then we added a Confluence knowledge base, re-ranking (with .rerank()), guardrails for security and standardization, and got it all working and logging.
That put all that logic into a single lambda, which of course takes longer than 3 seconds to run, which slack’s API considers a failure - it’s just too long! There’s no good way to get around that - async() methods aren’t reliable, and we can’t respond to the slack http session without closing it.
So we establish an asynchronous pattern - we’ll receive the slack webhook on the front-end with a stand-alone lambda called a Receiver, and it’s only job is to hand off the webhook payload to the real worker lambda, and then respond to slack with an A-OK (actually http/200), and then shut down.
That way our lambda can run and take all the time it needs, and slack doesn’t think we’ve failed to receive the webhook.
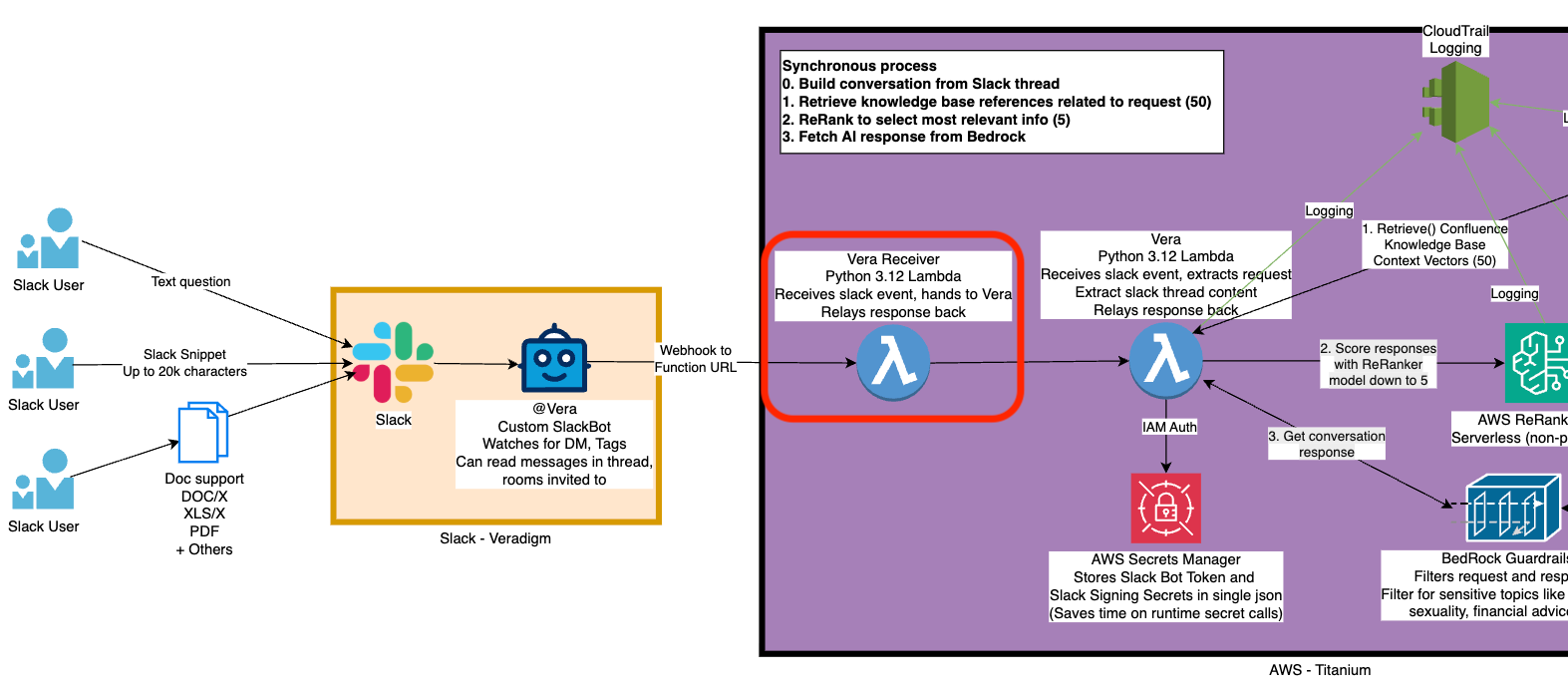
And it’s surprisingly easy to implement! Lets walk through what our new lambda looks like, and what we can remove from our worker lambda because of that disambiguation.
Receiver Lambda - Python
A receiver lambda isn’t any kind of special configuration. There’s no “Receiver” type or setting. It’s a pattern of building lambdas. Since our “total system” takes longer than the 3 seconds Slack gives us, we establish it.
But keep in mind, you can use this pattern in all sorts of places.
I’ve read and received feedback that Step Functions would be an even better solution to this problem than a Receiver, particularly for more complex lambdas, but I haven’t investigated those yet. If you have, please leave a comment below on what would change and where folks can read more!
Lets walk through what that Receiver Lambda looks like! First, lets write the python part, and then we’ll implement with terraform.
First, our imports. We’re not going to directly talk to slack here, so we don’t need the bolt framework - we’re just receiving a json payload, and then going to initialize the boto3 client since we’ll use it to trigger the next lambda.
| import json | |
| import os | |
| import boto3 | |
| # Initialize AWS Lambda client | |
| lambda_client = boto3.client('lambda') |
Next, lets establish the lambda_handler() function. This is the one called when this lambda is triggered. It receives the event (inner payload) and context (outer payload, like the HTTP headers and stuff).
On line 5, we dump the event to logs for troubleshooting.
Then on line 7, we enter a “try:” which contains pretty much this entire file. If there’s any error with receiving the file, we’ll jump to our error handling, which returns an http/200 to the slack webhook endpoint so they don’t keep sending us webhooks we don’t know how to handle.
On line 9, we decide the body of the webhook.
On line 12, we check if “challenge” is in the body. That’s the initial connection “challenge” that slack sends to make sure a webhook is configured appropriately. Since the Receiver Lambda is the one to receive inbound webhooks, it must know how to respond to challenges. If detected, we return an http/200 with the challenge payload.
| def lambda_handler(event, context): | |
| """ | |
| Receives Slack events, performs basic validation, and asynchronously invokes the processor Lambda | |
| """ | |
| print("Received event: %s", json.dumps(event)) | |
| try: | |
| # Parse the event body | |
| body = json.loads(event['body']) | |
| # Handle Slack URL verification challenge | |
| if 'challenge' in body: | |
| return { | |
| 'statusCode': 200, | |
| 'body': json.dumps({'challenge': body['challenge']}) | |
| } |
Next, on line 4, we get the event_type of the webhook message. Some types we just don’t care about.
For instance, on line 8, if the event type is “event_callback” and the event is an edited message, then we don’t care about this at all - we don’t (yet) have any behavior for edited messages, like rebuilding the response or anything like that. So we just throw away the message - we return an http/200 and shut down without triggering the Vera worker.
On line 18, if the event_type is an event_callback (which means we were triggered by a user event, which should be almost all the time), then we use the lambda_client we built earlier (the AWS boto3 client) to trigger the Vera worker node to build the conversation and send a response to slack.
Then on line 27, if there’s any other outcome we didn’t forsee, we send an http/200 back to Slack anyway so it doesn’t send resends, but we notably don’t trigger the Vera worker, so we don’t process the event further.
| def lambda_handler(event, context): | |
| # .... | |
| # Get the event type | |
| event_type = body.get('type', '') | |
| # Check for edited messages | |
| if ( | |
| event_type == 'event_callback' and | |
| 'edited' in body.get('event', {}) | |
| ): | |
| print('Detected edited message, discarding') | |
| return { | |
| 'statusCode': 200, | |
| 'body': json.dumps({'message': 'Edited message discarded'}) | |
| } | |
| # Only process events we care about | |
| if event_type == 'event_callback': | |
| # Asynchronously invoke the processor Lambda | |
| lambda_client.invoke( | |
| FunctionName=os.environ['PROCESSOR_FUNCTION_NAME'], | |
| InvocationType='Event', # Async invocation | |
| Payload=json.dumps(event) | |
| ) | |
| # Always return 200 OK to Slack quickly | |
| return { | |
| 'statusCode': 200, | |
| 'body': json.dumps({'message': 'Event received'}) | |
| } |
If any of this processing leads to an error, we log the event we had trouble processing to stdout (which in turn is written to cloudtrail, where we can debug), and return an http/200 without triggering the worker node.
| def lambda_handler(event, context): | |
| # ... | |
| try: | |
| # ... | |
| except Exception as e: | |
| print("Error processing event: %s", str(e)) | |
| # Still return 200 to Slack to prevent retries | |
| return { | |
| 'statusCode': 200, | |
| 'body': json.dumps({'message': 'Error processing event'}) | |
| } |
And that’s all for our Receiver. It’s exceptionally simple, which is ideal. We’re not doing any complicated processing or stitching together - we’re just accepting the package, doing a simple json relevancy check, tapping the worker lambda on the shoulder, and then telling slack “we got it”.
Now we have to build the lambda with terraform, lets walk through that next!
Receiver Lambda - Terraform + AWS
We have a lambda written, but we don’t yet have a lambda function resource in AWS. We’ll build all that with terraform, so lets write that config.
We’ll be walking through this file in this section: https://github.com/KyMidd/SlackAIBotServerless/blob/v1/terraform/lambda/lambda_receiver.tf
First, we need to establish some IAM stuff:
IAM Assume Role Policy - to permit our lambda to use the role
IAM Role - to hold permissions
IAM Policies - to permit triggering the Vera worker lambda and write logs to cloudwatch
Here’s the policy doc - we just say Lambda can use this role. To be more secure, we could filter the name of the lambda, but I haven’t done that here since the role isn’t that sensitive.
On line 12, we build a Role without any permissions yet, and link the assume role policy (line 14).
| data "aws_iam_policy_document" "DevOpsBotReceiverRole_assume_role" { | |
| statement { | |
| effect = "Allow" | |
| principals { | |
| type = "Service" | |
| identifiers = ["lambda.amazonaws.com"] | |
| } | |
| actions = ["sts:AssumeRole"] | |
| } | |
| } | |
| resource "aws_iam_role" "DevOpsBotReceiverRole" { | |
| name = "DevOpsBotReceiverRole" | |
| assume_role_policy = data.aws_iam_policy_document.DevOpsBotReceiverRole_assume_role.json | |
| } |
Next, we build a role policy and attach to our role, which permits this role to trigger the Vera “DevOpsBot” slack lambda, targeted on line 14.
| resource "aws_iam_role_policy" "DevOpsBotReceiver_Lambda" { | |
| name = "InvokeLambda" | |
| role = aws_iam_role.DevOpsBotReceiverRole.id | |
| policy = jsonencode({ | |
| Version = "2012-10-17" | |
| Statement = [ | |
| { | |
| Effect = "Allow" | |
| Action = [ | |
| "lambda:InvokeFunction", | |
| "lambda:InvokeAsync" | |
| ] | |
| Resource = [aws_lambda_function.devopsbot_slack.arn] | |
| } | |
| ] | |
| }) | |
| } |
Next, one more role policy - this time to permit us to write to cloudwatch.
| resource "aws_iam_role_policy" "DevOpsBotReceiver_Cloudwatch" { | |
| name = "Cloudwatch" | |
| role = aws_iam_role.DevOpsBotReceiverRole.id | |
| policy = jsonencode({ | |
| Version = "2012-10-17" | |
| Statement = [ | |
| { | |
| Effect = "Allow" | |
| Action = "logs:CreateLogGroup" | |
| Resource = "arn:aws:logs:us-east-1:${data.aws_caller_identity.current.id}:*" | |
| }, | |
| { | |
| Effect = "Allow" | |
| Action = [ | |
| "logs:CreateLogStream", | |
| "logs:PutLogEvents" | |
| ] | |
| Resource = [ | |
| "arn:aws:logs:${data.aws_region.current.name}:${data.aws_caller_identity.current.id}:log-group:/aws/lambda/DevOpsBotReceiver:*" | |
| ] | |
| } | |
| ] | |
| }) | |
| } |
Lambda still requires a zip file of all the code files, which seems really anachronistic to me, but here we are.
We build it with the archive_file data resources, on line 1. It outputs a receiver.zip file on line 4 in the module directory.
Then on line 7 we build the actual lambda function. It reads the zip file we just build (line 8).
We name it on line 9, and tag the role we just built on line 10. Then we specify the “handler” which says which file (the string before the dot) and function (the string after the dot) to run when the lambda is invoked.
We set our timeout to 10 seconds (line 12) since it shouldn’t run for longer than that, it’s doing nearly nothing, memory size to 128 (line 13, and runtime (python 3.12) and architecture (arm64 since it’s fast and matches our Vera worker) on line 14-15.
Line 17 bears more description. The lambda function doesn’t directly zip the file, and as long as the file exists, that resource says “cool”. But if your zip file has changed, we really want to update the lambda, so we use the source_code_hash attribute to say, “hash this file”, and if it’s changes, build a new version of our lambda. This works really well so far.
We also pass in the name of the lambda function worker that we should trigger as an env variable. This is more complex that we strictly need, but I was having fun and testing how to pass stuff to lambda, so you get to share the wealth :D
| data "archive_file" "devopsbot_receiver_lambda" { | |
| type = "zip" | |
| source_file = "python/receiver.py" | |
| output_path = "${path.module}/receiver.zip" | |
| } | |
| resource "aws_lambda_function" "devopsbot_receiver" { | |
| filename = "${path.module}/receiver.zip" | |
| function_name = "DevOpsBotReceiver" | |
| role = aws_iam_role.DevOpsBotReceiverRole.arn | |
| handler = "receiver.lambda_handler" | |
| timeout = 10 | |
| memory_size = 128 | |
| runtime = "python3.12" | |
| architectures = ["arm64"] | |
| source_code_hash = data.archive_file.devopsbot_receiver_lambda.output_base64sha256 | |
| environment { | |
| variables = { | |
| PROCESSOR_FUNCTION_NAME = aws_lambda_function.devopsbot_slack.function_name | |
| } | |
| } | |
| } |
Next up, we build a lambda alias of “Newest”. We’ll use this to point our Function URL at. Each time there’s a new version published, we move the alias to the newest version.
This is unintuitive to me. There’s a native alias called “latest” that points at the newest version of the code, but I don’t believe that’s compatible with the function URL. If you know differently, please comment!
Then we build the function URL on line 16, which is a public URL which can be send an http post to trigger the lambda. Now that we’re receiving (public) slack webhooks to this lambda, we need to move the function URL to this lambda.
Then on line 23, something new - we output the function URL as an output in this child module. We’ll surface it in the main.tf, so it’ll be printed when this is run, shortly.
| # Publish alias of new version | |
| resource "aws_lambda_alias" "devopsbot_receiver_alias" { | |
| name = "Newest" | |
| function_name = aws_lambda_function.devopsbot_receiver.arn | |
| function_version = aws_lambda_function.devopsbot_receiver.version | |
| # Add ignore for routing_configuration | |
| lifecycle { | |
| ignore_changes = [ | |
| routing_config, # This sometimes has a race condition, so ignore changes to it | |
| ] | |
| } | |
| } | |
| # Point lambda function url at new version | |
| resource "aws_lambda_function_url" "DevOpsBotReceiver_Slack_Trigger_FunctionUrl" { | |
| function_name = aws_lambda_function.devopsbot_receiver.function_name | |
| qualifier = aws_lambda_alias.devopsbot_receiver_alias.name | |
| authorization_type = "NONE" | |
| } | |
| # Print the URL we can use to trigger the bot | |
| output "DevOpsBot_Slack_Trigger_FunctionUrl" { | |
| value = aws_lambda_function_url.DevOpsBotReceiver_Slack_Trigger_FunctionUrl.function_url | |
| } |
In the top-level main.tf, we establish an output of the Vera Receiver lambda function URL… um, URL. This way when we run this apply in the terminal (or as part of your CI/CD), it’ll print the URL out for you to update your Slack App to.
| output "receiver_lambda_arn_for_slack" { | |
| value = module.devopsbot_lambda.DevOpsBot_Slack_Trigger_FunctionUrl | |
| } |
Here’s what an example terraform apply looks like:
| > terraform apply --auto-approve | |
| module.devopsbot_lambda.data.archive_file.NetBot_receiver_lambda: Reading... | |
| # ... | |
| Apply complete! Resources: 0 added, 1 changed, 0 destroyed. | |
| Outputs: | |
| receiver_lambda_arn_for_slack = "https://xxxxxxxxxxxxxxxxx.lambda-url.us-east-1.on.aws/" |
Vera Updates - Terraform
Updating the Vera worker is a really easy change - we remove the:
aws_lambda_alias - We only need this alias to point at with the function URL. Since we don’t need to build that, we don’t need the alias.
Notably, that means that as soon as we publish a new version of Vera, it will be used. This may or may not fit the stability and security model of your organization.
aws_lambda_function_url - The Vera lambda itself no longer receives direct inbound webhooks, so we can remove it
output.DevOpsBot_Slack_Trigger_FunctionUrl - Since we no longer build this, no need to output it
Here’s a deep link to that file for the PR that implements the Receiver pattern:
Vera Updates - Python
I haven’t yet implemented any updates here. We should be able to remove a lot of the duplication checking for the webhooks from Slack, since all of that logic should be implemented at the Receiver layer.
I’ll probably iterate on this in future (though it may not be blog-worthy!)
Slack App Updates
After applying these terraform changes, remember to update your Slack App to point at the Receiver Lambda Function URL, rather than the Vera direct URL. It’s been deleted, and now all ingress from the slack app should come through the stand-alone Receiver layer.
Summary
I don’t even know where to begin with this summary. I’ve written SO MUCH in this series, and I’ve grown as an engineer as we’ve progressed. There’s this appearance that I know all of this when I start, but that’s not the case at all. I have vague ideas for large parts of this project, and I have to do many, many hours of experimentation behind the scenes to get all this working and happy.
I wrote just over 35k words, which is just about too long to be called a novella 🤯
In this article we implemented a Receiver lambda pattern to do better abiding by Slack’s 3-second dead timer. That Receiver does some duplication checking, is able to trigger our Vera worker to run, and immediately responds to Slack that the webhook has been received.
This pattern adds stability and better compliance with Slack, not to mention reduces the amount of times our Vera workers spins up only to shut down again due to repeated Slack messages sent because Slack thinks our app is broken, which saves us money.
In summary: Better. Faster. Stronger.
Thanks everyone for following along on this very long journey. I appreciate you.
Please consider subscribing to fund further articles.
kyler