
🔥Let’s Do DevOps: Get All GitHub Repo Branches (Even if there’s Thousands)

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’ve been writing an ongoing project I’m calling our GitHubCop — it’s a tool that iterates over every repo we have (and we have thousands) and sets all the settings, branch policies, permissions, etc. on each of them every day.
I’ve been primarily relying on GitHub’s REST API + a lot of clever bash tricks. It isn’t the most modern language, but it makes sense to me, and heck, it works. As I’ve been developing the project I’ve found a few rough edges, and I wanted to write about one of them I stumbled on recently — grabbing a list of ALL the branches in a repo.
After all, we only want to set branch policies for branches that exist, right? So let’s talk about why this seemingly simple question isn’t simple, and how to solve it.
How Many Branches In This Repo?
Now, you wouldn’t be alone to think that it surely must be a single API call to find out how many branches you have. Or you could just get a single list of all the branches you have, right?
Unfortunately, it’s not as easy as you’d expect. The Get Repository REST call doesn’t contain it. Wanna know how many forks a repo has? That’s easy. Number of subscribers a repo has? Easy peasy. All of those are first class citizens in the Get Repository world. But not branch count.

I was sure I’d cracked it when I found the List Branches API call. In fact, I implemented this call, and was confused when it didn’t fetch all the branches
In fact, I implemented this call, and was confused when it didn’t fetch all the branches
In fact, the API call fetches the first 30 branches. Which, if you’ve worked with any enterprise (or open source!) software, is ridiculously low. We can bump up the number returned to 100 with ?per_page=100 query parameter, but how many pages do you need to make? Well, that’s some simple math that depends on how many total repos you have. Which again, I DON’T KNOW.
I eventually stumbled onto this wonderfully hacky method. Basically, you submit a request to get one branch with the List Branches API call. And again, the answer isn’t in the API response. However, it’s in the http header! If you issue a curl with verbosity turned up to 11, you print all the headers, including one called “link”, which is intended to tell you how many pages you can jump ahead (imagine the bottom of your google search results, with a button for result page 1, 2, 3, … 76, 77, 78).
So what we do is call GitHub to List Repos, and instead of setting our per_page to the max, of 100, we set it to the minimum, of 1! And then we see how many pages GitHub says it’ll take us to iterate through all the branches. Boom, that’s our branch count.
We’ve spent a lot of time here, both because I think it’s silly GitHub doesn’t have a simple REST attribute for branch count in a repo, and also because I am so deeply impressed by the hacky amazing solution to find this.
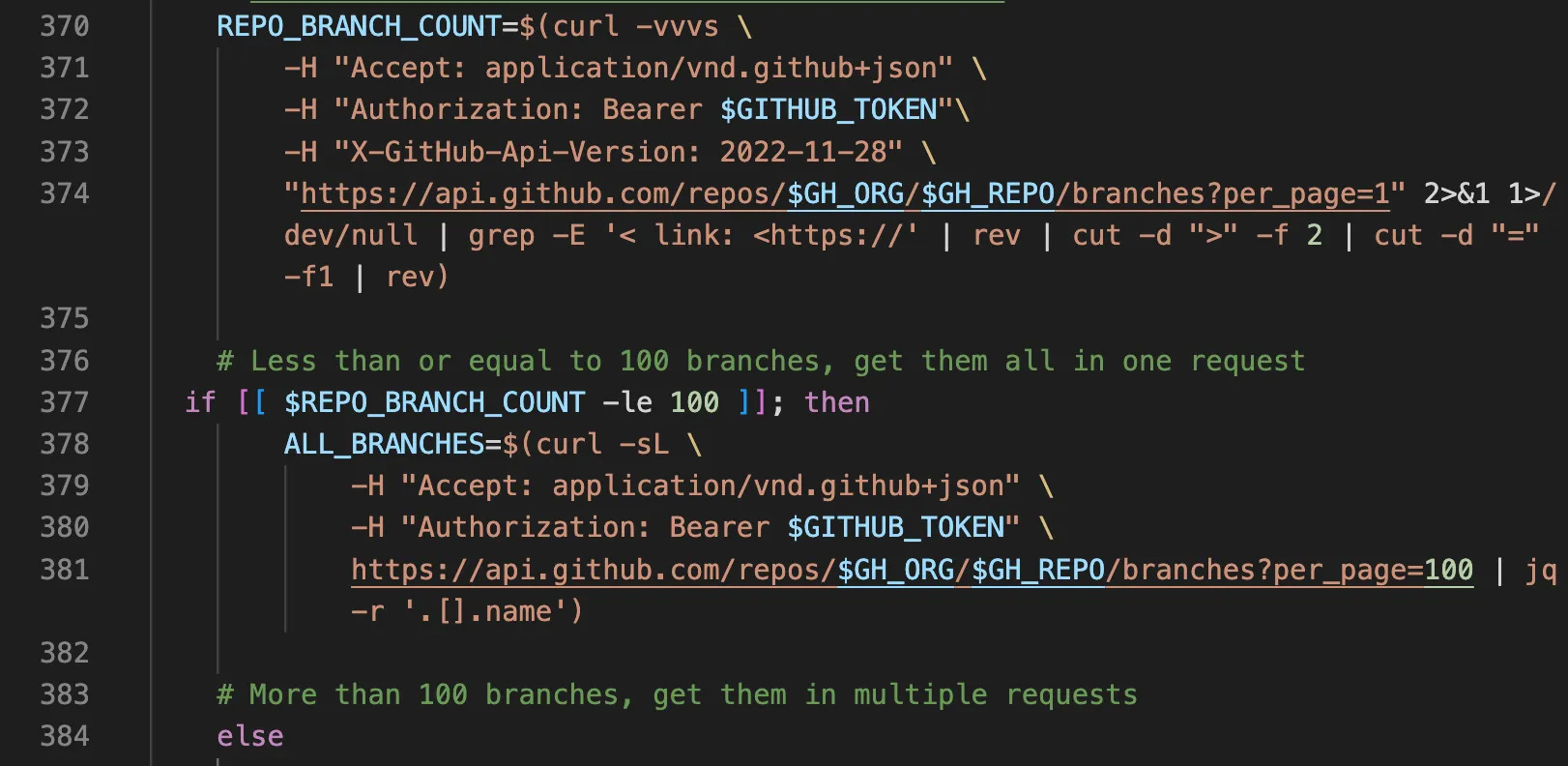
So how do we put it in code? Like this. There’s a lot going on here, so let’s wakl through it. First of all, we capture the eventual outcome as a var, REPO_BRANCH_COUNT, and we do a curl (web request) with verbosity (the -v parameter) turned all the way up -vvv . We sent an auth token (like 5) in the header, since this is an internal repo to my org.
And on line 7, we ask for a list of all the branches in the repo, but only send us 1 per page. Then we do some standard output manipulation. I actually don’t care about the REST response — which is returned via standard out, or stdout, which is represented here by 1. Since we don’t want it, we send stdout to null with 1>/dev/null. The output of this command is immediately thrown away (which is hilarious).
What we actually want is the verbose curl output, which is actually printed to a different output stream called standard error, which is represented as output 2. Since we wanna keep that, we send stderr to stdout with 2>&1. It’s confusing, but the short of it is we keep only the curl header. Then we do some bash manipulation.
First we filter the curl header to only the line that contains the info we want with grep -E '< link: <https://'. We then do something that’ll make absolutely no sense to you if you haven’t done it before. We reverse the string. Let’s jump ahead of this code snipped to talk about why.
| # This amazingly hacky way to get a repo count appears to be the only way, no official support in the APIs | |
| # https://stackoverflow.com/a/33252219/12072110 | |
| REPO_BRANCH_COUNT=$(curl -vvvs \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| "https://api.github.com/repos/$GH_ORG/$GH_REPO/branches?per_page=1" 2>&1 1>/dev/null \ | |
| | grep -E '< link: <https://' \ | |
| | rev \ | |
| | cut -d ">" -f 2 \ | |
| | cut -d "=" -f1 \ | |
| | rev) |
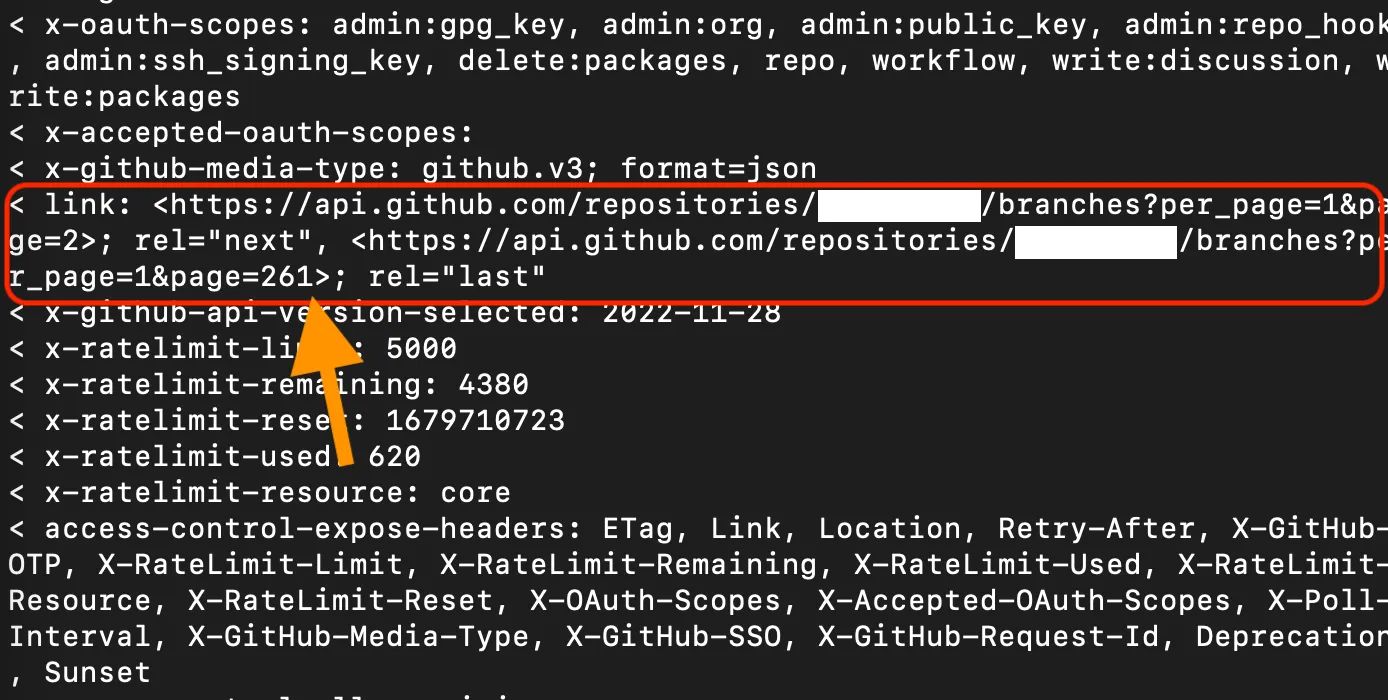
So we’ve filtered out outcome to just the curl header line starting with “link”. It looks like this (I added a return for readability, but it’s really just one line). The value we want (261) is way at the end. It’s hard to isolate stuff at the end using a bash tool called cut. If we cut the line at each >, which segment do we want? It isn’t easy to tell cut we want the last section.
| < link: <https://api.github.com/repositories/123456/branches?per_page=1&page=2>; | |
| rel="next", <https://api.github.com/repositories/123456/branches?per_page=1&page=261>; rel="last" |
But it is easy to tell cut we want the first section. Let’s reverse the string with rev. The string is no absolute nonsense, but if we cut it at the >, which segment do we want? Well, the second one. Let’s do it.
| "tsal"=ler ;>162=egap&1=egap_rep?sehcnarb/654321/seirotisoper/moc.buhtig.ipa//:sptth< ,"txen"=ler | |
| ;>2=egap&1=egap_rep?sehcnarb/654321/seirotisoper/moc.buhtig.ipa//:sptth< :knil < |
Cool, now we have a much shorter string. It’s still reversed, so still nonsense, but we do see the number we want to isolate at the beginning. And if we cut the string on the character =, which field do we want? Well, the first one. Let’s do it.
| 162=egap&1=egap_rep?sehcnarb/654321/seirotisoper/moc.buhtig.ipa//:sptth< ,"txen"=ler ; |
Hey, that’s our repo count! Well, kind of. Remember, this string is still reversed! Oh no, how do we fix this? Well, we reverse it again.
| 162 |
There’s our real number. We actually have 261 branches in this repo.
| 261 |
That was a lot! And it’s super hacky, which fits our theme well. I don’t know how reliable it’ll be, either. But it’s as reliable as any other hacky way to get branch counts, like scraping a web session for branch count number. So let’s use it!
Two Paths
Now that we know how many branches there are, we can divide our solution into two camps — the Simple Path (those repos with 100 or fewer branches) or the Paginated Path (those repos with more than 100 branches).
First let’s tackle the simple path. If we have 100 or fewer branches we can issue a single List Branches repo call and we’ll get all of them.
| # Less than or equal to 100 branches, get them all in one request | |
| if [[ $REPO_BRANCH_COUNT -le 100 ]]; then | |
| ALL_BRANCHES=$(curl -sL \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN" \ | |
| https://api.github.com/repos/$GH_ORG/$GH_REPO/branches?per_page=100 | jq -r '.[].name') |
And we’re done. Well, at least for repos with fewer than 101 branches. But if we have more than 100 branches, it’s a different matter altogether. It’s time for the Paginated Path! That means we’ll need to make more than 1 call, getting 100 branches at a time, and then aggregate them together.
First we set how many branches we can get per page, which is what GitHub limits us to — 100. Then we figure out how many pages to call based on total divided by that number. So we need to make 2.61 pages. And we can’t exactly do that, right? So because there’s a remainder, we drop the remainder and add one. So 2 pages + 1 extra page. That would capture a max of 300 branches, and we only have 261. That’s perfect.
Note this is perfectly scalable for thousands of branches — it just takes a bit to fetch all those pages.
| # More than 100 branches, get them in multiple requests | |
| else | |
| # Calculate number of pages needed to get all repos | |
| BRANCHES_PER_PAGE=100 | |
| PAGES_NEEDED=$(($REPO_BRANCH_COUNT / $BRANCHES_PER_PAGE)) | |
| if [ $(($REPO_BRANCH_COUNT % $BRANCHES_PER_PAGE)) -gt 0 ]; then | |
| PAGES_NEEDED=$(($PAGES_NEEDED + 1)) | |
| fi |
Then we need to issue List Branches paginated requests until we have all our branches. We do a simple for loop and use an in $(seq $PAGES_NEEDED) to count from 1 to the number of pages needed, incrementing on each loop. That lets us grab that page number on each call (line 9).
Now we have a single page of branches, and we need to keep track of them, appending them to a single var on each run so at the end we have a list of ALL the branches, not just the last paginated batch of them. So on line 13 we append ALL_BRANCHES to itself, and then also add a newline return and the fresh batch of $PAGINATED_BRANCHES.
| # Get all branches | |
| for PAGE_NUMBER in $(seq $PAGES_NEEDED); do | |
| #echo "Getting branches page $PAGE_NUMBER of $PAGES_NEEDED" | |
| PAGINATED_BRANCHES=$(curl -sL \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| "https://api.github.com/repos/$GH_ORG/$GH_REPO/branches?per_page=$BRANCHES_PER_PAGE&page=$PAGE_NUMBER" | jq -r '.[].name') | |
| # Combine all pages of repos into one variable | |
| # Extra return added since last item in list doesn't have newline (would otherwise combine two repos on one line) | |
| ALL_BRANCHES="${ALL_BRANCHES}"$'\n'"${PAGINATED_BRANCHES}" | |
| done |
If you’re an eagle-eyed programmer, you might have spotted a bug — on the very first run of our for loop, we append ALL_BRANCHES (an empty variable) to the first page of branches, but not before adding a newline to it. That means in our finished ALL_BRANCHES list, the very first entry of our branches list is a blank line. Lame!
However, there’s a tool for that. We update the ALL_BRANCHES var by piping it through the awk 'NF' command, which specializes in removing blank lines.
| # Remove any empty lines | |
| ALL_BRANCHES=$(echo "$ALL_BRANCHES" | awk 'NF') |
And bam, we have a var containing all the branches in a repo. If you now wanted to check if specific branches exist, it’s now a local call in memory-space, rather than networked (slow) API call.
However, that’s beyond our scope today. All exercises in protecting branches is an exercise left up to the reader.
| if [[ $(echo "$ALL_BRANCHES" | grep -E "^master$") ]]; then | |
| branch_protections_rest BRANCH='master' | |
| fi | |
| if [[ $(echo "$ALL_BRANCHES" | grep -E "^develop$") ]]; then | |
| branch_protections_rest BRANCH='develop' | |
| fi | |
| if [[ $(echo "$ALL_BRANCHES" | grep -E "^main$") ]]; then | |
| branch_protections_rest BRANCH='main' | |
| fi |
Summary
Phew! In this exercise we explored how a single question like “how many branches does this repo have?” can be an elusive one to build into automation! And then we implemented some wonderful, awesome, fantastically hacky solutions to work around GitHub’s lack of implementation of this attribute in their API.
Then we walked through some paginated API and bash logic, and collated all the results together (with some well placed awk to clean it all up), to make a readable, grep-able variable of all the repo branches.
Good luck out there!
kyler