


🔥Let’s Do DevOps: GitHub Reuseable Actions — Theory, Matrix, Concurrency, Make it all Dynamic 🚀
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can…

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’ve been spending my whole work days playing with GitHub Actions to attempt to build templates and permit my developers to scale horizontally out with minimal code changes. There’s so many cool features I’ve been discovering, like reuseable actions and dynamic matrixes.
For this post, I want to talk about a project I completed recently — we have a Terraform Plan & Deploy Action that accepts an input for which environment to target. However, we have ~50 environments that could be targeted. Sometimes we want to call lots of them, or make sure all environments are up to date. That horizontal scaling is an excellent technical challenge.
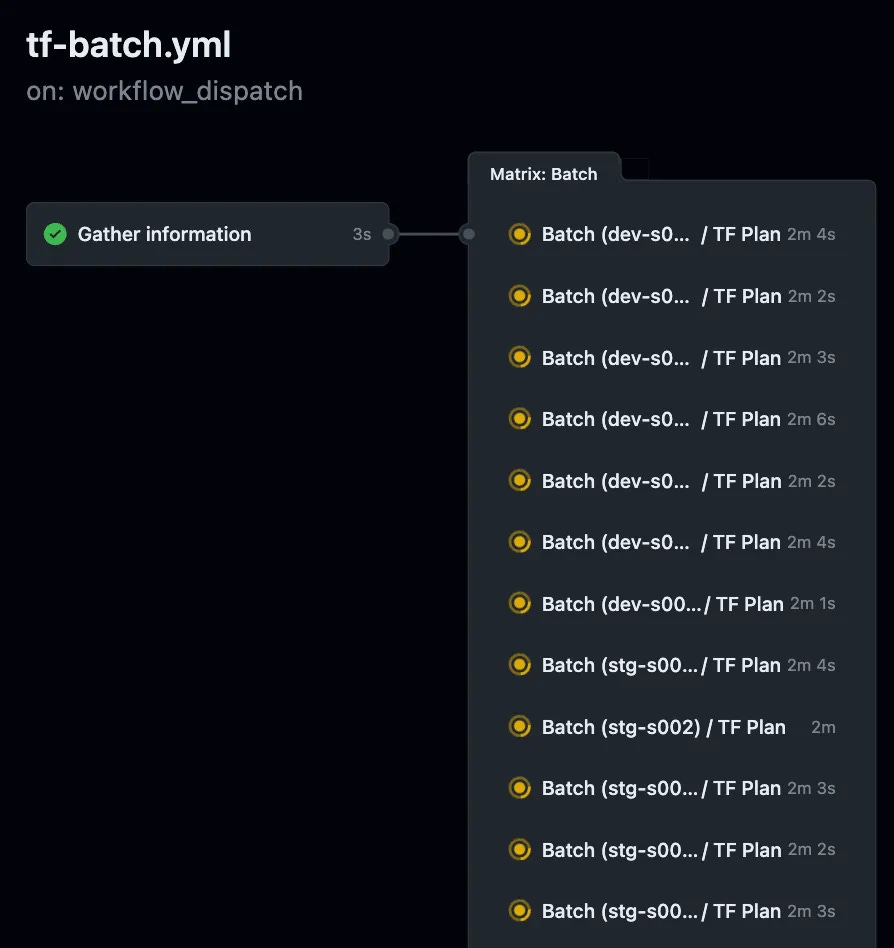
To build it, I created an Orchestration Action that finds all the potential target environments, uses substring or regex matching input (say you only want to target the dev- environments), and then concurrently executes Terraform Plan & Apply against all the environments you selected. It works incredibly well, and runs like ✨butter✨.
If you only care about the code, scroll all the way to the bottom, a GitHub Repo is linked there for you to copy the code and build it yourself!
Running Actions by Hand ✋
We’re going to cover a lot of ground here, so let’s start with some basic stuff we’ll build on. First of all, Actions are the automated pipelines that run on GitHub’s platform. They can do all sorts of stuff (they are magical ✨).
They initially were fully GitOps only — they were triggered based on pushes to a branch, or branches being merged together. However, that was quickly expanded to a few other ways to trigger pipelines — one of those ways is to kick it off by hand. It looks like this from the GitHub Actions page within a repo.
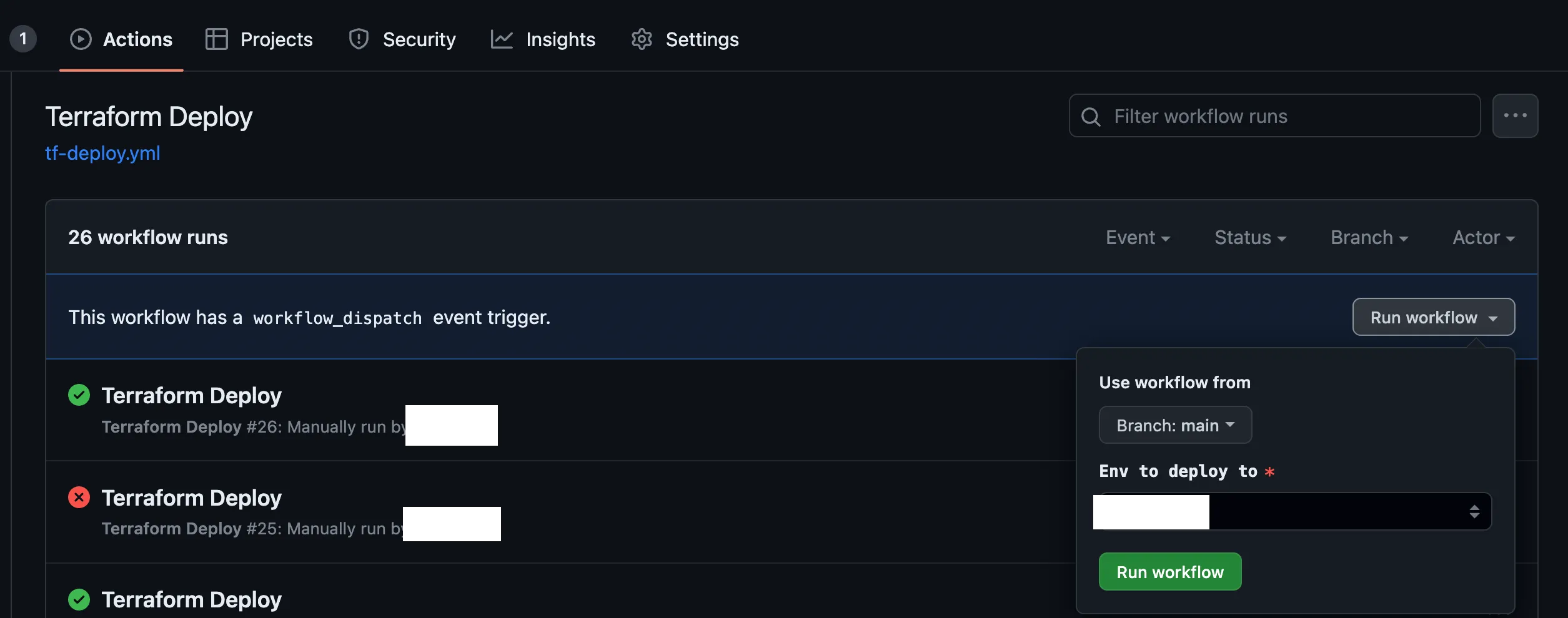
To enable this “click to run” functionality, update the Action workfile to include under the on header, a workflow_dispatch method. In this example, we’re also defining the inputs you can see above — targeting a particular environment we’d like to target.
| on: | |
| # Permit targeted manual trigger within console | |
| workflow_dispatch: | |
| inputs: | |
| location: | |
| description: 'Env to deploy to' | |
| type: choice | |
| required: true | |
| options: | |
| - dev | |
| - stg |
You can see above, there are two targets here — dev and stg. Those are options that are available when running this pipeline. That permits someone to manually trigger, in this case, a terraform deploy of the codebase to the dev or stage environment.
Computer, Kick off the Pipeline!
Now, that’s only 2 environments. If you wanted to run both of them, that would only take a few minutes. However, bump it up to 50 environments. How long would it take you to run all 50? Probably a long time, right?
It’d be much easier if we could programmatically kick them off. And we can! The gh cli (link) supports an option to start a workflow from the command line. That would totally work! The command would look like this:
| gh workflow run tf-apply.yml --repo OrgName/RepoName -f arg1=foo -f arg2=bar --ref main |
So we could loop through all our environments and start the workflow, woot. But how do we track all 50? Well, we’d have to go to the Actions tab in our repo and find the last 50 runs that were started. And we might have to worry about being rate-limited. Kicking off 50 jobs in the span of a few seconds that a local loop would take to run might be seen as a DoS on the github side. So maybe we should sleep for a while in each iteration of our loop?
And on down the ladder — we could probably solve this, but it doesn’t aggregate the runs in a useful way, or permit bulk approval of runs in case they use environments to track the different groupings of locations.
If only there was a better way! Well, of course there is — Reusable Workflows!
Reusable Workflows — The Best Way (So Far)
Reusable workflows grew out of callable Actions. Actions can call other Actions recursively, which is an awesome model that permits centralizing complex code and calling it from many places.
However, callable Actions and Workflow Actions have a very different syntax — an Action file looks like the following. You can see it looks like a lot like a single Step in a Workflow Action — it has a name, description, inputs, and then run steps. You can absolutely have multiple steps, but note there’s a bunch of stuff missing — there’s no on flag to trigger when it runs, there’s no compute type specified. It’s a kind of pruned down Workflow Actions file.
| name: 'Callable Action' | |
| description: 'I do stuff' | |
| inputs: | |
| input1: | |
| description: 'Input 1' | |
| required: true | |
| input2: | |
| description: 'Input 2' | |
| required: true | |
| runs: | |
| using: "composite" | |
| steps: | |
| - id: action_stuff_here | |
| shell: bash | |
| run: | | |
| #Parameters | |
| input1="${{ inputs.input1 }}" | |
| # Do other stuff here |
A Workflow Action syntax is… well, a regular Action like all the other ones you’ve seen. You specify Jobs, Steps, Permissions, on triggers, Names, etc. And it’s just a regular Action — so if you have an existing Action that takes an input and does stuff, hey, you’re already done, go you!
| name: Action Name Goes Here | |
| on: | |
| workflow_dispatch: | |
| pull_request: | |
| branches: main | |
| permissions: | |
| id-token: write | |
| contents: read | |
| repository-projects: read | |
| env: | |
| var1: foo | |
| var2: bar | |
| jobs: | |
| job-name: | |
| name: Job Name | |
| runs-on: ubuntu-latest | |
| steps: | |
| - uses: actions/checkout@v3 | |
| - name: Step Name | |
| run: echo "👋 hi mom" |
Reusable Actions Call
And that’s exactly where we’re at now — we have an Action that takes an input , and we need to call it. Let’s update our Terraform Deploy Action to permit calling as a Reusable Action — to do this, we enable the on flag for workflow_call. This permits another Action to call this Action.
| on: | |
| # (Skipping workflow_dispatch manual triggers) | |
| # Permits trigger from orchestration layer | |
| workflow_call: | |
| inputs: | |
| location: | |
| required: true | |
| type: string |
Then let’s create a new Action — I’m calling this the Terraform Batcher right now (naming is hard!). Calling it is super simple — we call the tf-deploy.yml workflow, and pass an input of location = dev.
| batch: | |
| name: Terraform Batcher | |
| uses: ./.github/workflows/tf-deploy.yml | |
| with: | |
| location: dev |
When we call this Action, it runs and it ✨tracks✨ the ✨job✨! Like, it runs the job, and shows all the steps, and it’s wildly easy to keep track of the spun off job. But we’re only building 1 of them! How do we make it more dynamic?
Reusable Actions Call — Matrix-ified
That’s okay, but we want to call both dev and stg, and run them concurrently. Thankfully, Actions has support for Matrix here — we can call a child Action in a matrix pattern, which means call it several times concurrently in separate workspaces. So on line 11, we define a map of location = dev, stg, and on line 7, we pass ${{ matrix.pod }} as location in the target Action. That means for the first run, it’ll pass location = dev and in the second run, it’ll pass location = stg. And remember, these are concurrent runs.
| batch: | |
| needs: gather-info | |
| name: Batch | |
| uses: ./.github/workflows/tf-deploy.yml | |
| secrets: inherit | |
| with: | |
| location: ${{ matrix.pod }} | |
| strategy: | |
| fail-fast: false | |
| matrix: | |
| location: ['dev', 'stg'] |
And that’s awesome, but still, we’re hard-coding the locations we want to run. Let’s do some dynamic construction and pass it to that job.
But Make it Dynamic 🚀!!
This is the finale version of the workflow I built, so let’s start at the beginning. To reiterate, this is a new Action, separate from our Terraform Apply Action that takes an input of a single, specific location to target.
My goal here is to control two things with these inputs — 1, which pod (location) do we want to target. We’re going to get all the Pod names, then use regex to filter which ones to target. This permits us to target any specific number of pods (or all of them). We default to * which we’ll interpret later as an “all”.
We also want to expose a method of running the TF Deploys — do we want to run them all concurrently, or run them in sequence, 1 at a time? We take a choice input here, so when folks kick off our Terraform Batcher Action, they see a drop-down with these two choices.
| name: Terraform Batch | |
| on: | |
| # Permit targeted manual trigger within console | |
| workflow_dispatch: | |
| inputs: | |
| pod-selection-regex: | |
| description: Regex to match pods to deploy, e.g. "dev-s00[1-5]" or substring match like "s001", use asterisk "*" to select all Pods | |
| type: string | |
| required: true | |
| default: '*' | |
| concurrency: | |
| description: Deploy strategy, concurrent or sequential | |
| type: choice | |
| required: true | |
| default: concurrent | |
| options: | |
| - concurrent | |
| - sequential |
Next we start building jobs. There are a few things here you won’t see until you’ve been playing with Actions for a while. First, on line 8, we define a few outputs. Those are values that will be surfaced as an output from this job and can be referenced by other jobs in the workflow. You can see on line 9–10 they reference a specific step name and then a specific output name from that Step.
For instance, MAX_PARALLEL output on line 9 comes from Step name set-deploy-strategy as name MAX_PARALLEL. That Step starts on line 16, and note that the Step “name” is actually the step “id”. In order to build an output, you must set a step id on the step that builds the output. You can see on line 19 how we’re using the github context to access an input value — the thing the user typed in when starting this workflow. If the user set the value to concurrent, we say MAX_PARALLEL should be 100. If they said sequential, we set MAX_PARALLEL to 1, and pipe that value to the $GITHUB_OUTPUT file, a special file GitHub Actions watches to harvest events from.
| jobs: | |
| gather-info: | |
| name: Gather information | |
| runs-on: ubuntu-latest | |
| # Set outputs for orchestration job | |
| outputs: | |
| MAX_PARALLEL: ${{ steps.set-deploy-strategy.outputs.MAX_PARALLEL }} | |
| TARGETED_PODS: ${{ steps.set-targeted-pods.outputs.TARGETED_PODS }} | |
| steps: | |
| - uses: actions/checkout@v3 | |
| - name: Set Concurrency to ${{ github.event.inputs.concurrency == 'concurrent' && 100 || 1 }} | |
| id: set-deploy-strategy | |
| run: | | |
| # If strategy is concurrent, max parallel is set to 100 (arbitrarily high number) | |
| if [[ ${{ github.event.inputs.concurrency }} == "concurrent" ]]; then | |
| echo "Concurrent deployment strategy selected, max parallel set to 100" | |
| echo "MAX_PARALLEL=100" >> $GITHUB_OUTPUT | |
| # If strategy is sequential, max parallel is set to 1 | |
| elif [[ ${{ github.event.inputs.concurrency }} == "sequential" ]]; then | |
| echo "Concurrent deployment strategy selected, max parallel set to 100" | |
| echo "MAX_PARALLEL=1" >> $GITHUB_OUTPUT | |
| fi |
Next we want to identify which “pods” (terraform workspace environments” to target. First, we read the tf-deploy.yml workfile into a variable, line 6. Then, on line 9, we filter the workfile through yq, a tool like jq but for yaml files, to grab only the potential target options — this should be an inclusive list of all possible target values, and use cut to get only the pod values.
The on line 12 we check to see if * value is set for our regex, which should indicate all pods. If yes, we keep all pods as valid targets. However, if a regex is set, on line 17, we filter $ALL_PODS through the regex using grep.
| - name: Specify pods to deploy using regex ${{ github.event.inputs.pod-selection-regex }} | |
| id: set-targeted-pods | |
| run: | | |
| # Read TF apply workfile as var | |
| WORKFILE=$(cat ./.github/workflows/tf-deploy.yml) | |
| # Get all targateable pods from workflow file | |
| ALL_PODS=$(echo "$WORKFILE" | yq .on.workflow_dispatch.inputs.location.options | cut -d " " -f 2) | |
| # If pod-selection-regex set to wildcard, select all pods | |
| if [[ ${{ github.event.inputs.pod-selection-regex }} == "*" ]]; then | |
| echo "Wildcard used to select all pods, selecting all pods" | |
| TARGETED_PODS=$ALL_PODS | |
| else | |
| echo "Wildcard not used to select all pods, selecting pods using regex" | |
| TARGETED_PODS=$(echo "$ALL_PODS" | grep -E "${{ github.event.inputs.pod-selection-regex }}" ) | |
| fi |
Then, line 3, we loop over our list and print all the values. This is a great debugging step — users can also validate the pods they want to target are the ones listed here.
Then we need to format the list of pods very carefully. We want the list to look like [‘pod1’,’pod2',’pod3'], but with how bash likes to remove quotes, we have to do this in a pecualiar way — first we write each pods to a file, and wrap it in both double and single quotes, line 10. Since we’re using printf rather than echo, no newlines are shimmed in, so the output looks like this: 'pod1','pod2','pod3', .
Note the trailing comma at the very end — that’s not what we want! So we use sed to grab the comma right at the end of the string, s/,$//' and remove it. Then we, line 17, wrap our pods list in square brackets and write it as an output.
| # Print out list of pods we'll be targeting | |
| echo "We'll be targeting the following pods:" | |
| while IFS=$'\n' read -r POD; do | |
| echo "- $POD" | |
| done <<< "$TARGETED_PODS" | |
| # Remove old file and put all pods into list like: 'pod1','pod2','pod3' | |
| rm -f TARGETED_PODS_HOLDER | |
| while IFS=$'\n' read -r POD; do | |
| printf "'$POD'", >> TARGETED_PODS_HOLDER | |
| done <<< "$TARGETED_PODS" | |
| # Read file as var and remove trailing comma | |
| TARGETED_PODS_OUTPUT=$(cat TARGETED_PODS_HOLDER | sed 's/,$//') | |
| # Send TARGETED_PODS to output | |
| echo "TARGETED_PODS=[${TARGETED_PODS_OUTPUT}]" >> $GITHUB_OUTPUT |
Then, the final step, we call tf-deploy.yml file in the same repo (and branch) on line 4, using a matrix strategy, with 1 build for ever “pod” targeted on line 12. Note that line 12 is gathering an output from the first job to run, and is using fromJSON to decode the output. This value isn't json, but Actions requires this expression on almost all outputs in order to understand them. It’s wonky, but it works 🤷♀.
The whole point of this job is to call our TF Deploy Action 1 time for each pod, and run them concurrently.
| batch: | |
| needs: gather-info | |
| name: Batch | |
| uses: ./.github/workflows/tf-deploy.yml | |
| secrets: inherit | |
| with: | |
| location: ${{ matrix.pod }} | |
| strategy: | |
| max-parallel: ${{ fromJSON(needs.gather-info.outputs.MAX_PARALLEL) }} | |
| fail-fast: false | |
| matrix: | |
| pod: ${{ fromJSON(needs.gather-info.outputs.TARGETED_PODS) }} |
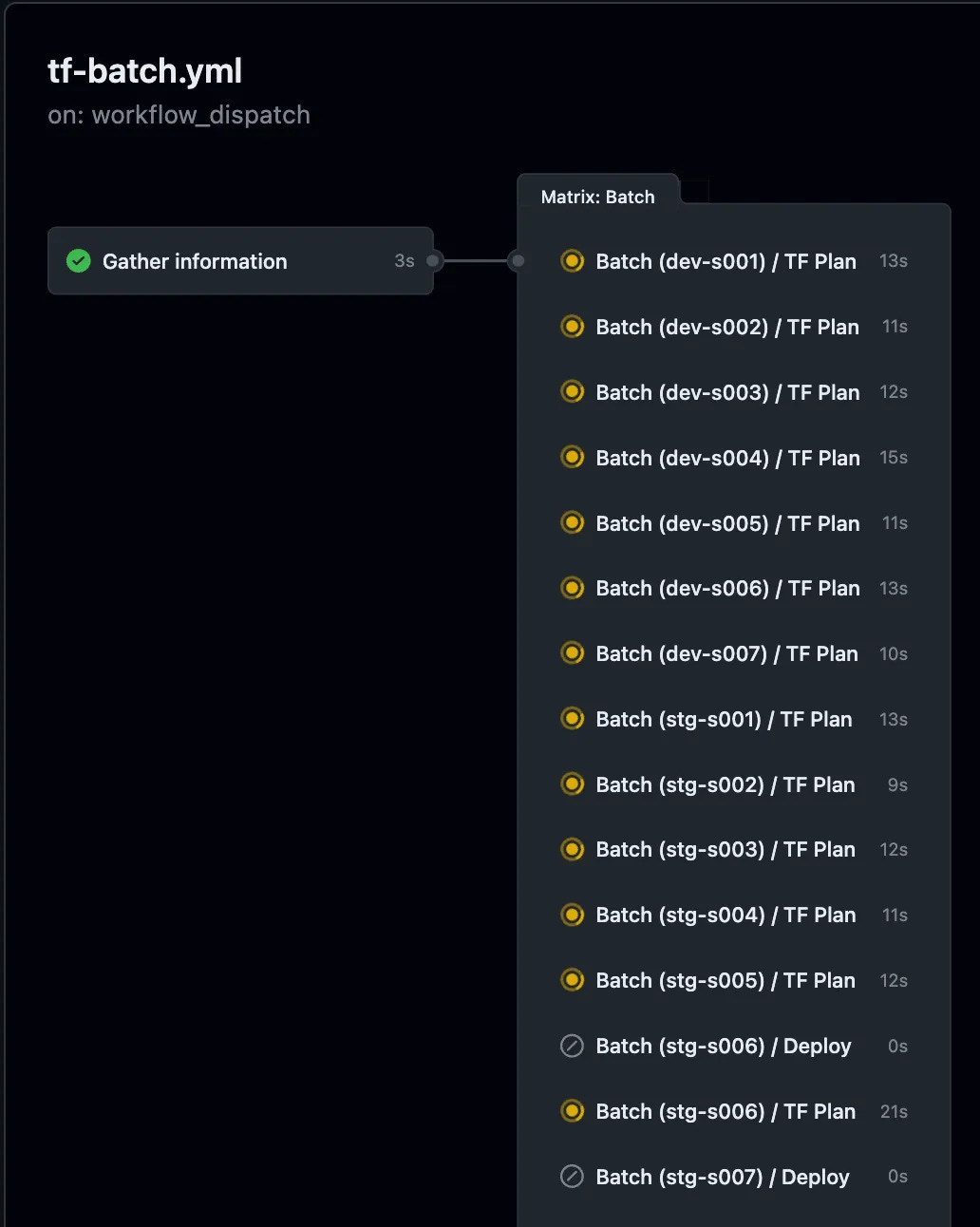
The output looks like this — Note how all the terraform workloads are runnign concurrently, and all are neatly tracked in a single pane of glass for a developer doing a batch deployment.
Summary
In this write-up, we learned together how to make a GitHub Action manually runnable from the web console. Then we saw how the gh cli tool can let us trigger an Action, and talked about the limitations from using that method.
Then we built something better — a Batch Action that can run our Terraform Deploy workload in parallel as a matrix, and track all the runs. This has a huge benefit in terms of usability and permits batch approving deploys for any workloads that use the same environments.
It absolutely rules. Here’s all the source code. Please steal it and build cool stuff!
GitHub - KyMidd/github-reusable-actions-terraform-concurrency
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…github.com
Good luck out there!
kyler