
🔥Let’s Do DevOps: Ingesting 100s of Thousands of Records into Terraform for Fun and Profit 🚀
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can…

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Note: I presented on this article and the recording is here.
Hey all!
It’s been a while — I’ve been busy with life, and chasing a 2-year-old toddler around the house takes up a lot of time and generates a lot of snuggles.
Recently, at work I was tasked with helping establishing geo-blocking and geo-permitting for some Azure Firewalls. Unlike Azure Application Gateways, they don’t have native support for geo-based location policies, so we needed to find a list of country-specific IPs.
I was sure that finding that data would be as simple as querying IANA, the Internet Assigned Numbers Authority, for a specific country code, to get all the assigned IPs. Unfortunately, that data wasn’t as easy to get as I assumed it would be. However, our NetOps team was way ahead of me here, and was able to get that working.
MaxMind For Global Domination
This article waswritten by Shannon Ford, an incredibly talented Network and DevOps engineer I have the opportunity to work with. Without his effort to build the data ingrestion from MaxMind, and the automation to refresh it weekly, I couldn’t have built any of the rest of this.
Unlocking the Power of GeoLite2 Free GeoLocation Data with GitHub Actions and Azure IP Groups
Terraform: Ingest a Country’s Entire IPv4 Internet Range!
So now we have 250 country-level flat files, each containing 10s of thousands of CIDRs that correspond to all the IPv4 CIDR ranges that are assigned to particular companies.
And that’s awesome! We need that! But it’s not in a format that is accessible by our Azure cloud infrastructure. Thankfully, Terraform has some tricks up its sleeve that permit it to ingest external data, including very large flat text files.
Now there’s 250 countries here to worry about, but let’s focus on just one to see if we can read it.
Since the files are local to the MaxMind internal repo, let’s create a terraform repo there. We don’t even need a providers.tf file, we can literally just create the following text in an output.tf file.
First, let’s read the US file (It’s 109k CIDRs!) with the file command, and use the split function to delimit the list by newline characters. Terraform calls this a tuple.
| locals { | |
| us_list = split("\n", file("./ip_lists_by_country/US_United States.txt") ) | |
| } |
We can use the terraform console to make sure it looks good, and it does! Well, mostly. It looks like the end of the list has an empty entry. That’s because the source data we’re ingesting has a newline character at the end of the last line. We could fix the source data, but it gets automatically reconstructed every week when Shannon’s awesome script runs, so let’s use terraform to strip it instead.
❯ terraform console
> local.us_list
tolist([
"1.1.1.0/32",
"1.1.1.2/31",
...
"223.130.11.0/32",
"223.165.6.0/24",
"223.165.96.0/19",
"",
])Let’s use another local call in order to use the compact function, whose entire purpose is to strip out empty entries.
| locals { | |
| us_list = split("\n", file("./ip_lists_by_country/US_United States.txt") ) | |
| us_list_without_empty_entries = compact(local.us_list) | |
| } |
With that, things look better. I mean, it’s a simply enormous list, but it’s properly formatted. Sweet.
❯ terraform console
> local.us_list_without_empty_entries
tolist([
"1.1.1.0/32",
"1.1.1.2/31",
...
"223.130.11.0/32",
"223.165.6.0/24",
"223.165.96.0/19",
"",
])Now we just need to do that for every single country that exists! How many could there be?
❯ ls -lah ip_lists_by_country | wc -l
253Oh. I don’t really wanna spend an hour creating static local blocks for every single country. Is there a way to do this dynamically with terraform? Let’s find out.
Terraform: Ingest EVERY Country’s Entire IPv4 Internet Range!
Terraform isn’t quite a real programming language, but it has slowly amassed some pretty incredible iterative and structural fundamental features.
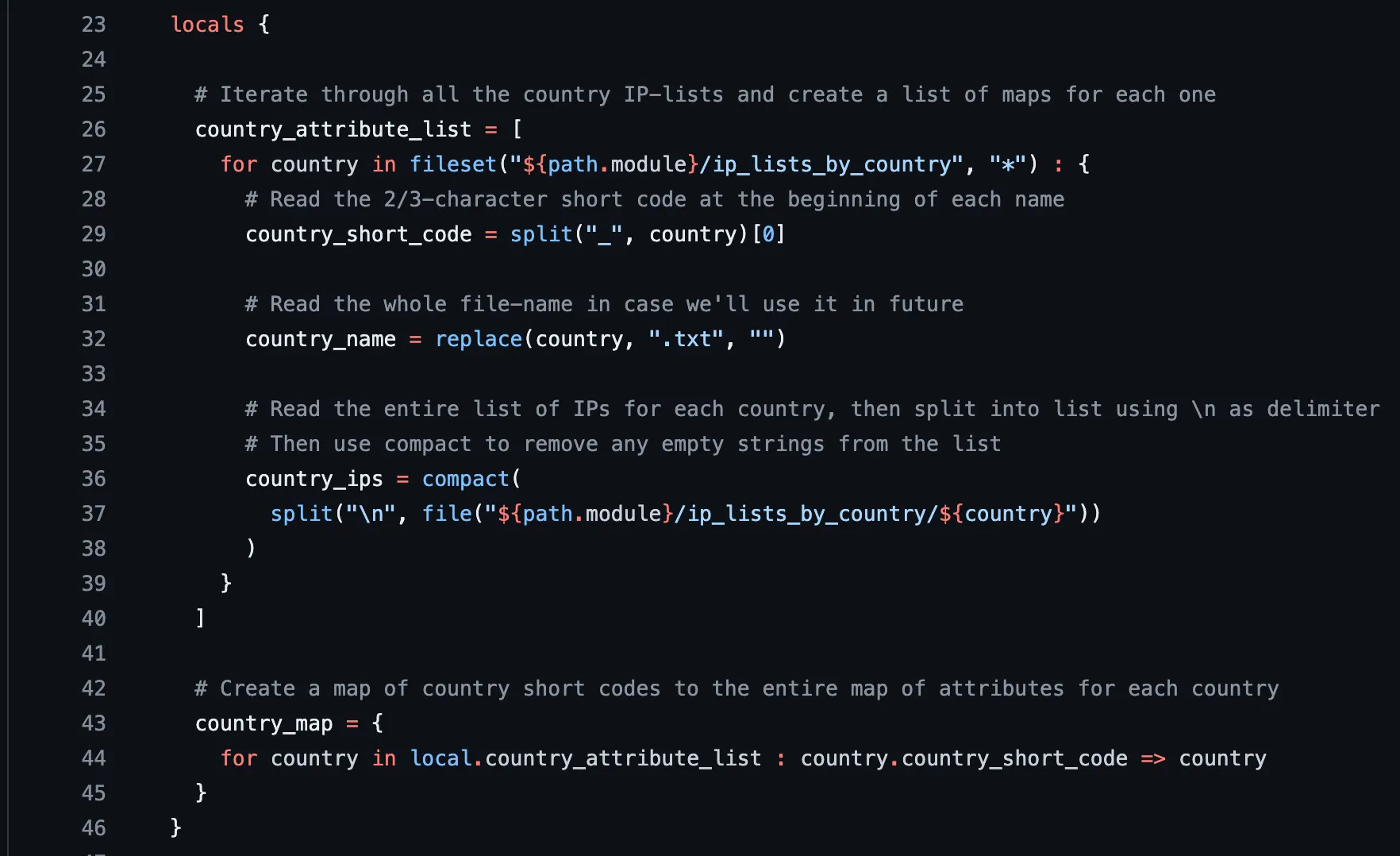
One of those is for loops, just like most programming languages support. And in our use case, we need to iterate over every file in a directory. Do I have to build that? Nope, there’s a feature called fileset that returns a list of all files in a directory. On line 5, we start iterating over every country(‘s file) in that directory.
And within that for loop, we can access some great stuff. For instance, the name of the file is set to country, so we build a new attribute (on line 7) called country_short_code by selecting everything before the first _ character. For instance US_United States.txt becomes US. We’ll use this soon.
And on line 10, we set the country name for easier reading later.
And on line 14, we do what we talked about above — we read the file’s contents (CIDRs for that country), split on the newline character, and remove any empty lines with compact.
| locals { | |
| # Iterate through all the country IP-lists and create a list of maps for each one | |
| country_attribute_list = [ | |
| for country in fileset("${path.module}/ip_lists_by_country", "*") : { | |
| # Read the 2/3-character short code at the beginning of each name | |
| country_short_code = split("_", country)[0] | |
| # Read the whole file-name in case we'll use it in future | |
| country_name = replace(country, ".txt", "") | |
| # Read the entire list of IPs for each country, then split into list using \n as delimiter | |
| # Then use compact to remove any empty strings from the list | |
| country_ips = compact( | |
| split("\n", file("${path.module}/ip_lists_by_country/${country}")) | |
| ) | |
| } | |
| ] | |
| } |
The output of this is an ENORMOUS list of 450k+ entries. The data is structured, but not very easy to use. To access the data in terraform, we’d have to do a for loop over the entire data set, to select for a country_short_code of a particular name. That’s not very easy for our teams to consume.
> local.country_attribute_list
[
{
"country_ips" = tolist([
"5.62.60.5/32",
"5.62.60.6/31",
...
"208.127.27.8/29",
"209.206.29.176/28",
])
"country_name" = "AD_Andorra"
"country_short_code" = "AD"
},
{
"country_ips" = tolist([
"2.16.44.0/24",
"2.16.158.0/24",
...However, we can do a neat trick that I am absolutely in love with. We can further process the data with another for loop to set the map’s keys as the country_short_codes and the map value as the entire data structure. This makes the map slightly more complex and slightly longer, but far easier to consume with terraform.
| locals { | |
| # Create a map of country short codes to the entire map of attributes for each country | |
| country_map = { | |
| for country in local.country_attribute_list : country.country_short_code => country | |
| } | |
| } |
The data now looks like this. Note the new map keys.
> local.country_map
{
"AD" = {
"country_ips" = tolist([
"5.62.60.5/32",
"5.62.60.6/31",
...
"208.127.27.8/29",
"209.206.29.176/28",
])
"country_name" = "AD_Andorra"
"country_short_code" = "AD"
}
"AE" = {
"country_ips" = tolist([
"2.16.44.0/24",
"2.16.158.0/24",
...That seems kind of \_(ツ)_/¯ unless you’ve worked with terraform before. Accessing the first data structure for a specific country would take a for loop with filtering. Accessing this new data structure for a particular country looks like this. It’s wildly easy to filter and access now.
> local.country_map["US"]
{
"country_ips" = tolist([
"1.1.1.0/32",
"1.1.1.2/31",
...
"223.165.6.0/24",
"223.165.96.0/19",
])
"country_name" = "US_United States"
"country_short_code" = "US"
}Just want the IPs for the US region? Incredibly, intuitively easy.
> local.country_map["US"].country_ips
tolist([
"1.1.1.0/32",
"1.1.1.2/31",
"2.16.33.76/32",
...Using it as a Module
I’m unable to publish this data, since MaxMind is paid for access, but I can show you how you’d use a module of your own if you build it.
To call your module from another terraform run:
module "geoip_map" {
source = "git@github.com:(Your-org)/(Your-repo).git?ref=(Your-branch)"
}To access the US IPs from the module:
module.geoip_map.country_map["US"].country_ipsSome resources will require you to chunk the data into a group of some lists, you can do that with chunklist function:
locals {
chunked_permitted_cidrs_us = chunklist(module.netops_geoip_map.country_map["US"].country_ips, 5000)
}And then build a series of IP Groups or other resources using that list:
resource "azurerm_ip_group" "allow_ips_us" {
count = length(local.chunked_permitted_cidrs_us)
name = "US_IPs_0${count.index + 1}"
cidrs = local.chunked_permitted_cidrs_us[count.index]
}As of today, that would build 22 IP Groups to contain the 108k CIDRs assigned to the US. All automated, perfect, and updated without intervention.
Summary
The total size of the output is 464,343lines! That’s bonkers, but since most filtering is local, generating the list isn’t the hard part. Now, using it for much of anything will take a while — since it’ll need to generate a 1:1 API call to your platform provider to check the IPs in any IP Groups.
In this blog, we established that terraform can ingest hundreds of thousands of lines of non-terraform data, even without the use of data resources. It can clean that data, and build complex data structures that can be easily queried and filtered, and then use that data to do cool things, like building IP Groups in Azure (among many other awesome things).
Hope you build something cool with this info.
Good luck out there.
kyler