
🔥Let's Do DevOps: Inventory Dependency Licenses across all Repos in GitHub Org🔥
aka, SBOM-arama

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I was asked by our Legal and Compliance teams to investigate whether all our dependencies for our software was licensed properly for us to use it. And I confidently answered, I have absolutely no idea.
As with any enterprise, we have a process for reviewing dependencies to make sure the licenses and functionality match, but that process has been intermittently enforced in the past, and as big enterprises gobble up small companies via acquisition, we have to do our best to bootstrap all our processes on the new product and team.
Validating that all the licenses they’ve ever integrated into their tools are legally available for us to use can fall by the wayside. However, we’re doing our best to find them so we can replace them with tools that are available to us!
First step, we need to find all of them. And GitHub is super helpful here - their dependabot service relies on finding all the dependencies of a codebase based on analyzing the package manager files in a repo. They also return that info at their SBOM API call for each repo. So the data is there, we just have to go find it.
I wrote a python script that can find all the Repos in an Org, and then iterates over each one to download the SBOM (via REST API) for each one, then aggregates all the data into a single CSV. When run as a GitHub Action, that CSV is stored as an artifact that can be downloaded and used for other automation, or just analyzed with Excel/Google Sheets to find all the copyleft software. Here’s what a run looks like:
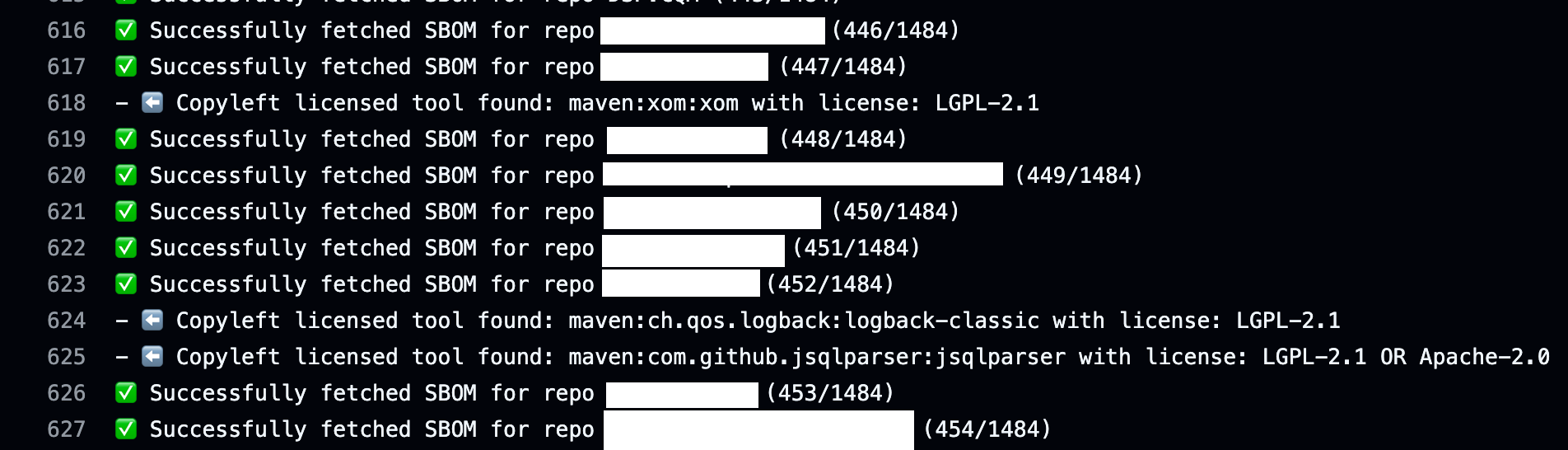
And you end up with a spreadsheet that looks like this:
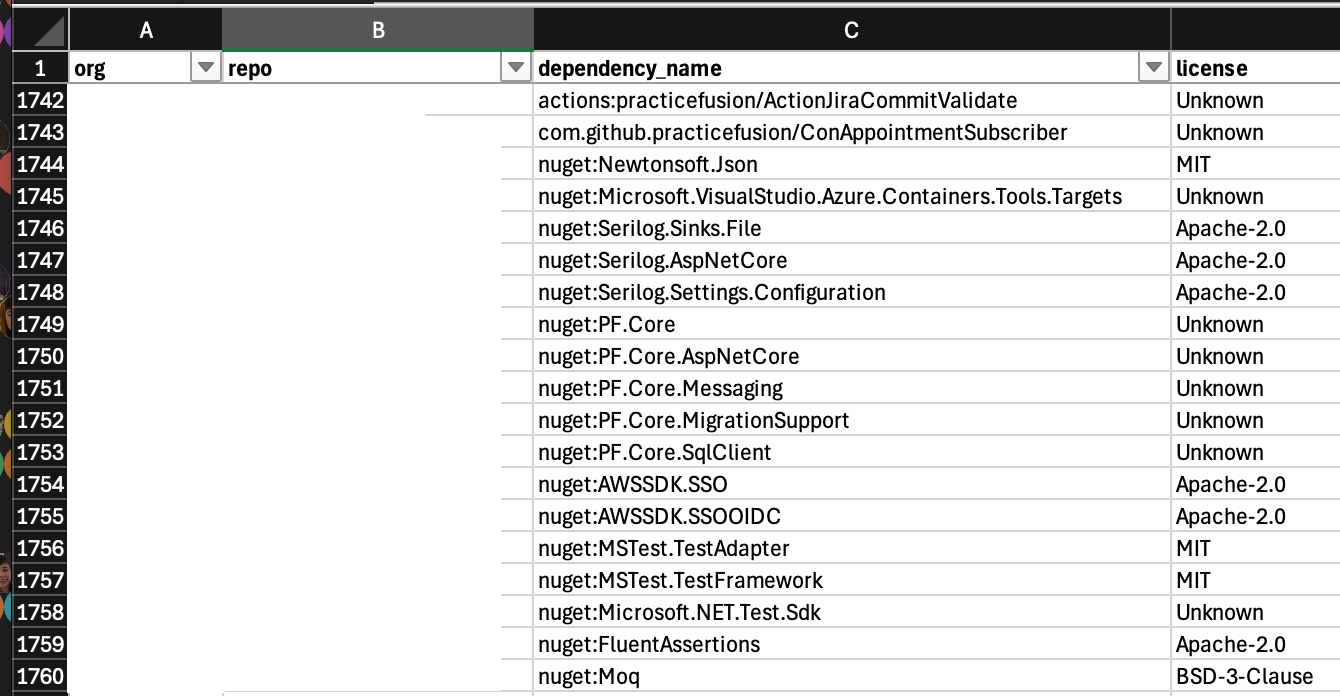
In the Org I ran this in, we scanned 1.5k repos and found 53k dependencies, including a few dozen licenses that we shouldn’t have found, so we’re working our way through them.
What will you find in your own org? Here’s a link to the Action to test it out now if you want.
Let’s talk about how this Action works, as well as how it works!
Imports and Validation
Let’s talk python. I normally use Bash (it’s just so quick to test stuff out!) but I’m trying to branch out into other languages. And given how much json we’re working with here, I’m pretty happy to not need to break out any jq. While jq is amazing, intuitive it is not.
So let’s do some imports - we need `requests` to talk to the http json API, we need `os` to read environmental variables (like the GitHub Org, and the PAT we’ll use for authentication), we need `json` to read and filter the json API responses.
We also need `csv` to write out our CSV file of each repo’s dependencies and licenses, and we need `time` to implement our waiting functionality if our API wallet runs dry. We’ll talk about each of these in depth as we go.
| # Imports | |
| import requests | |
| import os | |
| import json | |
| import csv | |
| import time | |
| ### | |
| ## Introduction | |
| ### | |
| print("##################################################") | |
| print("Finding all repos' SBOMs and storing in CSV") | |
| print("The CSV will be stored as an artifact in the GitHub Actions run") | |
| print("##################################################") |
Lets Walk(through) This Python
We’re not going to walk through the file in the order the text appears, top to bottom, but rather logically, how the functions are called and what they do, in order. That’ll help us follow the logic (I promise, follow me here).
First we check to make sure variables are set. We don’t require any inputs and our only response is a True if all are present. We require the `GITHUB_TOKEN` (which is the PAT) in order to make authenticated read call to GitHub’s API, and we require `GITHUB_ORG` to know what GitHub Organization to target for reading. If all goes well, we return True, line 11.
And down in our program, we show how we call it. Basically we say that if the response of this function is True (which confirms those values are populated from environmental variables), then we read them and set them to values. This should never fail because we just confirmed they’re present, so there is no error handling.
| # Function | |
| def initial_var_validation(): | |
| # Get env variable GITHUB_TOKEN, and if not present, exit | |
| if 'GITHUB_TOKEN' not in os.environ: | |
| print("GITHUB_TOKEN not found in environment variables") | |
| exit(1) | |
| # Read repo we should evluate as an environmental var | |
| if 'GITHUB_ORG' not in os.environ: | |
| print("GITHUB_ORG not found in environment variables") | |
| exit(1) | |
| return True | |
| # Calling it | |
| if initial_var_validation() == True: | |
| GITHUB_ORG = os.environ['GITHUB_ORG'] | |
| GITHUB_TOKEN = os.environ['GITHUB_TOKEN'] |
Next up is a helper function for checking the API token wallet. GitHub provides authenticated users 5k tokens per hour to make API calls. Reads are usually 1 token (but are sometimes a bit more for large responses). If we run out of API tokens, our script can fail in weird ways.
To avoid that, we’ll call this function several times before doing API operations to make sure our wallet has a sufficient budget to continue. If not, it sleeps for 60 seconds and checks again, and loops forever until we have tokens in our wallet again.
On line 3 we enter a forever loop. In programming 101 they say to never do this, but it’s useful here - we want to look until we break. On line 4, we send a git request to api.github.com/rate_limit (reference doc). On line 12 we check if we got any http response code, and if we got an http/200 (happy response), we continue.
We convert our response to a json package, and then read .rate.remaining to find our remaining API wallet token budget. Then we check to see if we have less than 100 tokens. If we do, we sleep for 60 seconds and check again. If we have 100 or more tokens, we break from this forever loop and go back to our real program.
| # Check if hitting API rate-limiting | |
| def hold_until_rate_limit_success(): | |
| while True: | |
| response = requests.get( | |
| url="https://api.github.com/rate_limit", | |
| headers={ | |
| "Accept": "application/vnd.github.v3+json", | |
| "Authorization": f"Bearer {os.environ['GITHUB_TOKEN']}" | |
| } | |
| ) | |
| if response.status_code != 200: | |
| print("Error fetching rate limit info") | |
| exit(1) | |
| rate_limit_info = response.json() | |
| remaining = rate_limit_info['rate']['remaining'] | |
| if remaining < 100: | |
| print("ℹ️ We have less than 100 GitHub API rate-limit tokens left, sleeping for 1 minute and checking again") | |
| time.sleep(60) | |
| else: | |
| break |
Next up we build the http headers. We end up calling this a lot, so it makes sense to abstract it out. We establish a map called `headers` on line 4, and we set Accept header to what github returns, a github json standard, and then we set our PAT as a bearer token for Authorization on line 6. Then we return the headers and store it as… well, `headers`. Hey, names are hard.
| # Define function | |
| def build_headers(): | |
| # Create headers for sbom request | |
| headers = { | |
| "Accept": "application/vnd.github.v3+json", | |
| "Authorization": "Bearer "+GITHUB_TOKEN, | |
| } | |
| return headers | |
| # Build headers | |
| headers = build_headers() |
Next up, we are ready to start learning about the Organization. First of all, how many repos are we talking? This is interestingly relevant because we can only ask for 100 Repos at a time, and its not clear how many pages there are of Repos, so we have to do ✨math✨.
Line 4 - check our API token wallet.
Line 7 - Reach out to get the GitHub Org global info, making sure to send our authentication and other relevant headers on line 9. We check our response code on 13 to make sure we get a happy http/200 response.
On line 18 - 19, we read both the Private repos (line 18) and Public repos (line 19), and then add them together (line 20).
Functions can only return one thing, but that thing can be a complex object, so that’s exactly what we do. We build a dictionary that contains all that information and return it to the caller. But what’s the caller?
| # Find count of all repos in org and store as var | |
| def get_repo_count(): | |
| # Get API token wallet | |
| hold_until_rate_limit_success() | |
| # Find how many repos exist in the Org | |
| org_info = requests.get( | |
| url="https://api.github.com/orgs/"+GITHUB_ORG, | |
| headers=headers | |
| ) | |
| # Check response code, and if not 200, exit | |
| if org_info.status_code != 200: | |
| print("Error fetching org info") | |
| exit(1) | |
| # Store info | |
| PRIVATE_REPO_COUNT=org_info.json()['owned_private_repos'] | |
| PUBLIC_REPO_COUNT=org_info.json()['public_repos'] | |
| TOTAL_REPO_COUNT=PRIVATE_REPO_COUNT+PUBLIC_REPO_COUNT | |
| # Build dict of info and return | |
| d = dict(); | |
| d['PRIVATE_REPO_COUNT'] = PRIVATE_REPO_COUNT | |
| d['PUBLIC_REPO_COUNT'] = PUBLIC_REPO_COUNT | |
| d['TOTAL_REPO_COUNT'] = TOTAL_REPO_COUNT | |
| return d |
The caller is another function! So we want to get all the repo names, so that we can read their SBOMs. And now we know how many there are, because of the above function. Woot. Okay, let’s do it.
This is a little intense, so let’s move fast.
Line 5 - check to make sure our API token wallet is full by calling the function we defined earlier.
Line 7 - call the above function to get a repo count.
Line 10 - establish a list to put all the repo names in.
Line 16 and 17 - Set that we can fetch 100 repos per page (the max), and then start iterating through the pages we’ll require, which is the total repo count divided by the per-page limit (+ 2 to make sure we call enough pages).
Line 21 - Get all the repos on whatever page we’re on, then on line 26 make sure the response code worked.
Line 32 - Iterate over every repo in the response, and check to see if the top-level keys “archived”, “disabled”, or “is_template” are set. If yes, skip it. If not, add the “name” attribute to the list!
Line 40 - Once the iteration has run over all pages, and all repos, we kick back all the repo names to the caller, and on line 43 we see the caller. It stores all the repo names in “repo_names” variables as a list of repo names.
| # Define function | |
| def get_all_repo_names(): | |
| # Check API token wallet | |
| hold_until_rate_limit_success() | |
| repo_count_info = get_repo_count() | |
| # Can get 100 repos at a time, so need to loop over all repos | |
| repos = [] | |
| # Announce | |
| print() | |
| print("Fetching all repos") | |
| per_page=100 | |
| for i in range(1, repo_count_info["TOTAL_REPO_COUNT"]//100+2): | |
| print("Fetching repos page "+str(i)) | |
| # Fetch all repos | |
| response = requests.get( | |
| url="https://api.github.com/orgs/"+GITHUB_ORG+"/repos?per_page="+str(per_page)+"+&page="+str(i), | |
| headers=headers | |
| ) | |
| # Check response code, and if not 200, exit | |
| if response.status_code != 200: | |
| print("Error fetching repos") | |
| exit(1) | |
| # Iterate over response, find all repos | |
| for repo in response.json(): | |
| # If not archived, disabled, or template, append | |
| if repo["archived"] == False and repo["disabled"] == False and repo["is_template"] == False: | |
| repos.append(repo["name"]) | |
| # Announce | |
| print() | |
| return repos | |
| # Get all repo information | |
| repo_names = get_all_repo_names() |
Next up we initialize our CSV by creating the file and writing the headers.
On line 3, we open a file called (github_org_name)_repo_dependency_listing.csv in write mode (not “a” for append, so we’ll over-write anything that exists with that name, doesn’t matter in a GitHub Action) as “file”.
On line 5, we create our writer and link it to that file.
On line 8, we create our CSV headers - org, repo, dependency_name, and license.
On line 9, we write that information to the CSV file.
And on line 12, we call the function, no inputs or outputs.
| # Define function | |
| def initialize_csv(): | |
| with open(GITHUB_ORG+"_repo_dependency_licensing.csv", 'w', newline='') as file: | |
| # Initialize writer | |
| writer = csv.writer(file) | |
| # Write header | |
| field = ["org", "repo", "dependency_name", "license"] | |
| writer.writerow(field) | |
| # Call function | |
| initialize_csv() |
Next up we’re going to start iterating over our repos and getting their dependencies. First let’s talk about the function to do that. It doesn’t tackle all the repos at once, it’s build to get one Repo’s SBOM.
On line 2 we define our function and receive some info - we’re looking for the repo name (repo), the iteration index (index), and the count of all repos (repo_count).
On line 8, we store the URL we’ll do the request to, and on line 11 we do the request for a single repo (whose name is passed into this function). On line 17 we check our response code. It’s a little more complex here than in earlier functions, we establish some error handling to print the error message if we fail to retrieve the SBOM for any repo so folks can diagnose it. Error handling also enables our script to continue without globally failing if there’s an issue.
This is getting long, so let’s split this function into two snippets, on to the next one!
| # Define function | |
| def get_repo_dependencies(repo, index, repo_count): | |
| # Check rate limit | |
| hold_until_rate_limit_success() | |
| # URL | |
| url = "https://api.github.com/repos/"+GITHUB_ORG+"/"+repo+"/dependency-graph/sbom" | |
| # Fetch sbom | |
| response = requests.get( | |
| url=url, | |
| headers=headers | |
| ) | |
| # Check response code, and if not 200, exit | |
| if response.status_code == 200: | |
| # Print green check box | |
| print("✅ Successfully fetched SBOM for repo", repo, "("+str(index)+"/"+str(repo_count)+")") | |
| else: | |
| print("❌ Error fetching SBOM for repo", repo, "("+str(index)+"/"+str(repo_count)+")") | |
| # Print error message | |
| print("Error message:", response.json()['message']) | |
| return |
Okay, so we’ve got our response, and validated the http header is happy to get here. Let’s read the SBOM and write the dependencies (and their licenses) to the CSV!
On line 2, lets read through the SBOM json response for the sbom.packages address to get ALL the dependencies. There’s a lot on most repos (our largest has 2.2k!).
On line 4 we check to see if the .licenseConcluded key is present. If not, the SBOM API isn’t sure what the license is of the package, so we mark it as Unknown.
On line 10, we check to see if the string “GPL” exists in the license string. GPL is the strongest copyleft license, and for a for-profit company it can spell trouble, so we print a little warning that it’s been found. More on copyleft licenses here.
Then on line 14 we open up our CSV again, this time in “a” mode for Append, so we just add info to the file, and on line 19 we establish our field to write, which is our github Org, then the repo name, then the package name (since we’re iterating over each package 1 by 1, and then the license for that package, and on line 20 we write the row.
| # Parse response by looping over sbom.packages to get all names and license types | |
| for package in response.json()['sbom']['packages']: | |
| # If license key not present, set to unknown | |
| if 'licenseConcluded' not in package: | |
| license = "Unknown" | |
| else: | |
| license = package['licenseConcluded'] | |
| # If license contains string GPL, print out repo name | |
| if "GPL" in license.upper(): | |
| print("- ⬅️ Copyleft licensed tool found:", package['name'], "with license:", license) | |
| # Write to CSV | |
| with open(GITHUB_ORG+"_repo_dependency_licensing.csv", 'a', newline='') as file: | |
| # Initialize writer | |
| writer = csv.writer(file) | |
| # Write data | |
| field = [GITHUB_ORG, repo, package['name'], license] | |
| writer.writerow(field) |
Finally, we call the get_repo_dependencies() function. It works on a single repo, so we loop over every repo (using an index, established on line 3 and incremented on line 6).
| # Get dependencies for each repo, write to CSV | |
| repo_count = len(repo_names) | |
| index=1 | |
| for repo in repo_names: | |
| dependencies = get_repo_dependencies(repo, index, repo_count) | |
| index+=1 | |
Put it in a GitHub Action!
Okay, we have a functional python script that can read all the info we need, and write them to a file! At least for everyone that has python3 installed, a virtual env setup, and all the required dependencies installed. Which means it’s kind of hard to use, right?
So let’s make it super easy to use - let’s put it in a GitHub Action so folks can call it easily and use it even if they don’t understand it.
This is a “composite” GitHub Action, and can be listed in the GitHub Marketplace (which I’ve done, here is the link).
On line 1 - 2 we establish some basic stuff, like the name and description of this Action.
Then on line 4 we setup what we’ll need to receive to operate - we only need 2, the GitHub Org name, and the GitHub Token (PAT). Both are set to required, as our script can’t succeed without them.
| name: Org-Wide License Analyze | |
| description: 'This github action is used to analyze the license of every repository in a github org' | |
| inputs: | |
| GITHUB_ORG_NAME: | |
| description: 'The name of the github org to analyze' | |
| required: true | |
| type: string | |
| GITHUB_TOKEN: | |
| description: 'The github token to use for the analysis, needs all repo: permissions and org:read' | |
| required: true | |
| type: string |
Next up we start building steps for our Action to run.
Line 4 - checkout the repo, in case any files are required (they probably aren’t? Maybe this should be removed).
Line 6 - setup python with version 3.12 on the runner.
Line 10 - Install any dependencies we’ll require, using pip and referencing the requirements.txt file in the Action’s repo.
| runs: | |
| using: "composite" | |
| steps: | |
| - uses: actions/checkout@v4 | |
| - uses: actions/setup-python@v5 | |
| with: | |
| python-version: '3.12' | |
| - name: Install dependencies | |
| shell: bash | |
| run: | | |
| python3 -m pip install --upgrade pip | |
| pip install -r ${{ github.action_path }}/requirements.txt |
Next up we copy the license file to our working directly on line 4.
Then on line 6 we run our python3 script, and set the GitHub Org name and the GitHub Token as environmental variables for our python3 script to read.
Then on line 13 we run an upload/artifact step that’ll collect our CSV and store it as an Artifact on this GitHub Action run for humans (or automation) to download and further process.
| - name: Copy the license file to the action directory | |
| shell: bash | |
| run: | | |
| cp ${{ github.action_path }}/org_get_all_repos_sbom.py . | |
| - name: Run License Analysis | |
| shell: bash | |
| run: python3 org_get_all_repos_sbom.py | |
| env: | |
| GITHUB_ORG: ${{ inputs.GITHUB_ORG_NAME }} | |
| GITHUB_TOKEN: ${{ inputs.GITHUB_TOKEN }} | |
| - name: Upload License Overview as Artifact | |
| uses: actions/upload-artifact@v4 | |
| with: | |
| name: org-license-csv | |
| path: '*.csv' | |
| branding: | |
| icon: 'arrow-down-circle' | |
| color: 'gray-dark' |
Links
Here’s a link to the code repo:
Here’s a link to the marketplace entry where you can use this yourself:
https://github.com/marketplace/actions/org-wide-license-analyze
Summary
In this write-up we talked about what an SBOM is, and how it’s useful to know the licensing of the dependencies are teams are using. We talked a little about how GitHub provides this information, but doesn’t provide it for the entire Organization (at publication time, at least!).
We walked through how we can use python to fetch this information, how we’ll pass secure information to python, and some error handling that we’ve built in to handle edge cases. We also embedded the python script in a GitHub Action and listed it on the Marketplace so folks can easily consume this tool without needing to install or run anything locally on their system.
Hope it was an illuminating read. Thanks ya’ll.
Good luck out there.
kyler