

🔥Let’s Do DevOps: Shard GitHub Actions Workload over Many Concurrent Builders
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can…

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’ve recently been building a tool I’m calling the GitHub Cop. It’s a tool that processes all 1.5k+ repos in my GitHub Org and sets all the settings, branch protections, auto-link rules, permissions, etc. That’s a lot of changes each night, and on every repo sequentially.
To do that, I’ve built several tools, including an API token circuit breaker to avoid running out of API tokens when doing tens of thousands of actions in a short time, and how to paginate API calls when processing thousands of attributes, but none of those processes help speed up the single-threaded processing of thousands of repos.
What would help is having several threads working concurrently. Thankfully, GitHub Actions makes this pretty easy to do! I did have to teach bash some arithmetic, but I was able to make it work.
Let’s talk about theory, then how I implemented this change in my custom bash program, and the limitations I faced and how I solved them.
GitHub Actions Theory: Matrix
Sharding (a word not recognized by my computer’s dictionary), is the practice of splitting a single workload into several parts, and then assigning each those work “shard” or fragments to one of several builders. It’s usually assumed that the workload would then be processed concurrently. It’s a method of reducing the total time a workload runs by splitting it across several runners.
Because this is a relatively foundational topic of computing, GitHub Actions makes this relatively easy using the matrix strategy. In math, a “matrix” means a rectangular array or table where numbers are stored and often combined in a predictable way.
In a GitHub Actions context, a matrix is values that are combined and handed off to the tasks you list on the job. If you have a single matrix value like attribute: [foo, bar], the job will be run twice, once where attribute is set to foo and once where attribute is set to bar.
You can take it further by having several variables, like the following example (taken from the GitHub Actions page on matrix strategy). This set of two values are combined in every pattern, which will kick off 6 jobs.
| jobs: | |
| example_matrix: | |
| strategy: | |
| matrix: | |
| version: [10, 12, 14] | |
| os: [ubuntu-latest, windows-latest] |
The jobs will be kicked off, one with each of these sets of matrix values:
{version: 10, os: ubuntu-latest}
{version: 10, os: windows-latest}
{version: 12, os: ubuntu-latest}
{version: 12, os: windows-latest}
{version: 14, os: ubuntu-latest}
{version: 14, os: windows-latest}Update Action to Support Sharding
Sounds simple enough, right? Okay, maybe it sounds like a whole heap of nonsense. Let’s implement it together, and see if it makes more sense in practice. It sure clicked for me when I went and did it!
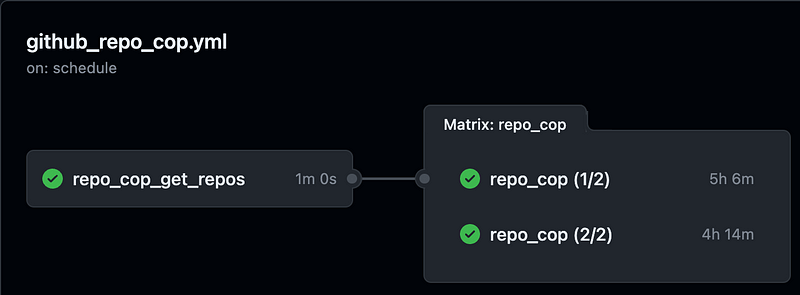
So for my GitHubCop before any sharding, the Action was really, really simple. On a nightly schedule, the job repo_cop runs, which downloads the code for this repo (line 10), and then runs a script from the repo called repoCop.sh (line 14) and injects a Secret, which is the GitHub PAT with admin rights, on line 13. Super duper simple, right?
| name: GitHub Repo Cop | |
| on: | |
| # Run nightly at 5a UTC / 11p CT | |
| schedule: | |
| - cron: "0 5 * * *" | |
| jobs: | |
| repo_cop: | |
| runs-on: ubuntu-latest | |
| steps: | |
| - uses: actions/checkout@v2 | |
| - name: GitHub Repo Cop | |
| env: | |
| GITHUB_TOKEN: ${{ secrets.MY_GITHUB_TOKEN }} | |
| run: ./repoCop.sh |
And we could update this to run as a matrix, however, there are some steps that don’t need to be run multiple times. The first thing the GitHub RepoCop does is get a list of all the Repos in the Org. You could have every single runner do this, but there’s just no reason to do that, so let’s separate that code.
I’m skipping over how I did that in my codebase — really if what you’ve built is all function-based, just move any functions for “prep the work list” to a separate file or command so it can be run first on a single builder. For my workload, that’s just “get all the repos”. Done.
I initially was going to use GitHub Actions Outputs to pass the variable for which Repos to work to my fleet of builders, but then I ran into this snippet:
Outputs are Unicode strings, and can be a maximum of 1 MB. The total of all outputs in a workflow run can be a maximum of 50 MB.
Given that I want to construct a list or array, and the output would be a unicode string, I decided to pass. I’m pretty sure that it would work? But I decided it’s safer and would lead to less headaches to write the contents of the variable to a file, and pass that binary file to the builders. To do that, two changes.
Change 1: In my application code, I write all the repos I want to process to a file called all_repos. That’s super duper easy:
| # Write Org repos to file | |
| echo "$ALL_REPOS" > all_repos |
Change 2: I need to update my Action to have step 1 be only the “get all the repos” stuff, and then I need to stash the binary file for the next stage of builders. Here’s my new action file.
You can see on line 14, we’ve updated the script we’re calling to be one that just gets all the repos (and writes a file called all_repos to the root of the working directory). And then we have a new step (line 17) that uploads the file as an artifact. We use a computed name on line 20 for the github.run_id — a unique numerical identifier for the workflow run. That’ll make sure that this same artifact isn’t downloaded by a future run, and isn’t over-written either, in case we want to go back and check its contents. This value exists in the GitHub Context.
| name: GitHub Repo Cop | |
| on: | |
| # Run nightly at 5a UTC / 11p CT | |
| schedule: | |
| - cron: "0 5 * * *" | |
| jobs: | |
| repo_cop: | |
| runs-on: ubuntu-latest | |
| steps: | |
| - uses: actions/checkout@v2 | |
| - name: GitHub Repo Cop | |
| env: | |
| GITHUB_TOKEN: ${{ secrets.MY_GITHUB_TOKEN }} | |
| run: ./repoCop_getRepos.sh | |
| # Action "Outputs" are unicode strings, so can't be a "list", or at least would be more complex to handle the data structure | |
| # Rather than deal with that, going to upload the binary list file, and will read in next step | |
| - name: Upload repos list | |
| uses: actions/upload-artifact@v3 | |
| with: | |
| name: all-repos-${{ github.run_id }} | |
| path: all_repos |
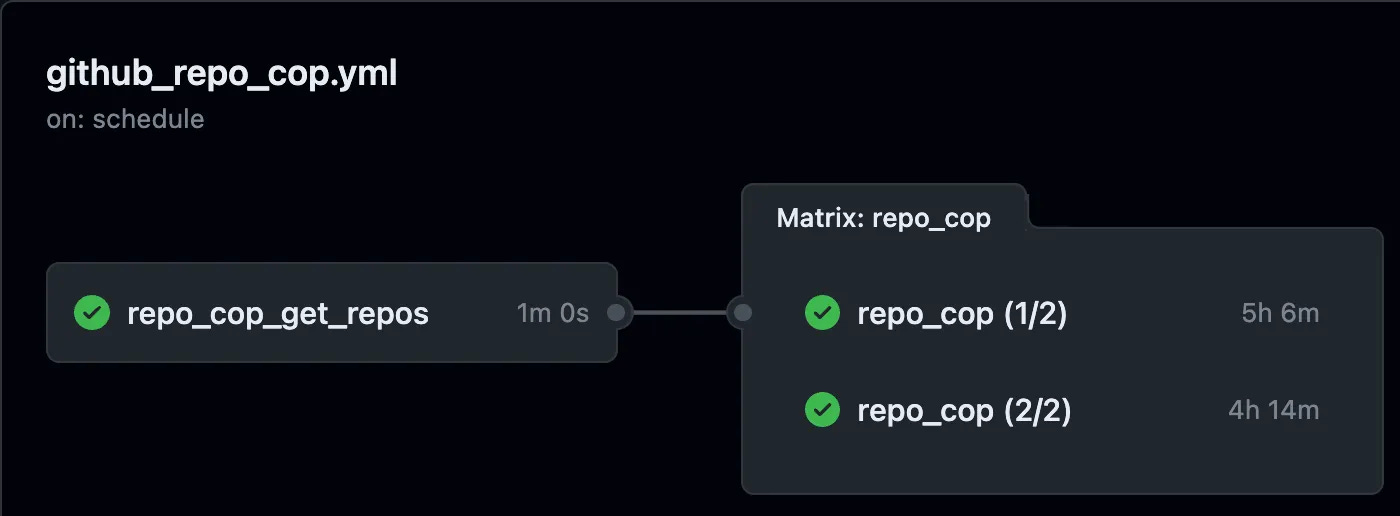
But that’s only half of the story — we’ve now updated our Action from doing the work single-threaded, to only creating a list of repos to work and not doing the work. However, we’ve now eliminated all the single-threaded tasks and can start on the multi-threaded tasks.
Here’s the sharded version of the second step in our Action. Since we’re now ready to shard, we use a matrix strategy (line 5), with fail-fast disabled, so that if one of the shards has a catastrophic failure we keep going. And on line 8, we define a shard value of 1/2 or 2/2. The work “shard” is meaningless here — it’s a name we created for a variable that’ll be passed to our builders.
In order for our builders to decide what parts of the work to build, they need to understand two things — first, how many segments of work exist — that’s the denominator, or the value below the line in a fraction. If there are 2 segments of work, the number below the line is 2. Imagine a pie split into 2 pieces.
Second, the builder needs to know which segment it should be working. If there are two pieces of pie, should it work the first piece, or the second? That’s the numerator, or the number above the line in a fraction. Given that’s how I (a human, hi!) am understanding the issue, I decided to use that same metaphor to pass to the builders doing the work — so on line 8, we pass either shard = 1/2 or shard = 2/2 to the builders. Those 2 jobs are run concurrently.
| repo_cop: | |
| runs-on: ubuntu-latest | |
| timeout-minutes: 720 # 12 hours - Default is 360 minutes / 6 hours | |
| needs: repo_cop_get_repos # Require the repos list to be generated first | |
| strategy: | |
| fail-fast: false # Keep going even if one shard fails | |
| matrix: | |
| shard: [1/2, 2/2] |
The steps in the second action start the same — we download the code (we have to since we’re running a script from our repo) on line 2, and then we deviate. Since the list of repos we’ll be running is stored as an artifact, both our concurrent builders go and fetch that artifact. We use the same github.run_id attribute as we used to store the artifact, so it’s for sure the same version of that file.
Then on line 9, we call our application code — a bash file called repoCop.sh, in this case, and we are again passing our Secret as an environment value, but we’re also doing something interesting — on line 12, we pass in an environment value SHARD as the value of matrix.shard. The GitHub Action will set that to 1/2 on the first builder and 2/2 on the second builder.
| steps: | |
| - uses: actions/checkout@v2 | |
| - name: Download repos list | |
| id: download-repos | |
| uses: actions/download-artifact@v3 | |
| with: | |
| name: all-repos-${{ github.run_id }} | |
| - name: GitHub Repo Cop | |
| run: ./repoCop.sh | |
| env: | |
| GITHUB_TOKEN: ${{ secrets.MY_GITHUB_TOKEN }} | |
| SHARD: ${{ matrix.shard }} |
And that’s it! At least for the Action. The application code still has to be taught to understand what’s going on with that value.
Some tools will have a native understanding of sharding. For instance, yarn is a browser testing tool, and it can front several back-end testing tools. If it’s fronting jest, another testing tool, it natively understands what sharding is, and you can pass it a shard value and a job total value, and it’ll do it. However, my bash script is written by me, and doesn’t yet understand that as a command line argument. So let’s make it do so.
run: yarn test --shard=${{ matrix.shard }}/${{ strategy.job-total }} --coverageTheory: Updating Application to Support Sharding
Updating the Action to support sharding is only half the battle. It doesn’t inherently split the application workload in two — it only injects some variables into the workload. Your application code must also be updated in order to understand what those variables instruct it to do — what parts of the workload it should work on.
The way my application is written is a big while loop, which operates on a list of repositories. Here’s a simplified version. Basically, we are serially processing one repo at a time from the var ALL_REPOS, which is a return delimited list of the repositories we should inspect and update.
| while IFS=$'\n' read -r GH_REPO; do | |
| (Action stuff) | |
| done <<< "$ALL_REPOS" |
It follows, then, that if we want builderA to do the first 50% of the list, and builderB to do the second 50%, we could break the ALL_REPOS list into 2 parts. We could probably do that as part of the Action as a separate step (and in retrospect, that would have been cleaner!), however I put that logic right into my application.
Let’s walk through the steps I follow for bash to understand fractional workloads, and how it’s implemented.
Practice: Updating Application to Support Sharding
At first I built this logic to split the list down a binary perfect 50%, but it turns out that often cuts the middle entry in half, whoops. So rather than that, let’s cut the line by a fractional 50% of the total. To do that, we need to know the total, so let’s count on line 5.
| # Read the list of repos into a var | |
| ALL_REPOS=$(cat all_repos) | |
| # Count lines in the list of repos | |
| ALL_REPOS_LENGTH=$(echo "$ALL_REPOS" | awk 'NF' | wc -l | xargs) |
Next we need to read in the SHARD value that we’re passing to our builders. Remember, we’re using SHARD values like “1/2” and “2/2”.
The Shard number we should be working is above the line — either the first half or the second half, line 2. and the total count of shards is the number below the line, line 5.
| # Shard number | |
| SHARD_NUMBER=$(echo "$SHARD" | cut -d "/" -f 1) | |
| # Number of shards | |
| SHARD_COUNT=$(echo "$SHARD" | cut -d "/" -f 2) |
Since we now know we’re either working the first 1/2 or the second 1/2, we count up how many lines of the list that would equate to. For example, if we have 10 repo lines, the first half would be 1–5, and the second half would be 6–10, line 3.
On line 4 we handle an outlier — if there are 11 lines, bash match gets a little wonky — it doesn’t natively do floating point math, so half of 11 if 5.5, but bash would understand it as “5”. That would mean we’d miss 1 of our lines, that’s not great! So we add a number to our half. That will mean each builder will work 6 repos, with the middle repo worked twice. For my idempotent workflow, who cares. If your workload isn’t idempotent (you should fix it!), this is a more serious issue and you should solve it better.
Then on line 8, we use a native bash command called split that’s intended to split binary files, but can operate on lists. We tell it to put n number of lines per list, and read the all_repos file we’ve read into disk on this Action, and to output 2 lists, 1 that is the first half, and one that is the second half. They’re named like all_repos_00 and all_repos_01.
| # Number of lines per shard, add 1 to round up fractional shards | |
| # Lines aren't duplicated, last shard is slightly short of even with others, which is fine | |
| LINES_PER_SHARD=$((ALL_REPOS_LENGTH / SHARD_COUNT)) | |
| LINES_PER_SHARD=$((LINES_PER_SHARD + 1)) | |
| # Shard the list based on the shard fraction | |
| # This outputs files like all_repos_00, all_repos_01, all_repos_02, etc | |
| split -l $LINES_PER_SHARD -d all_repos all_repos_ |
Since the split tool starts counting at 0, we subtract 1 from our “shard number”, the part of the pie we’re going to work , on line 2. Then on line 5 we read into memory the ALL_REPOS var from the specific file for this builder that it should work.
And finally, on line 9, we count all the repos we should work.
| # Select shard to work - minus one since `split` starts counting at 0 | |
| SHARD_TO_WORK_ON=$(("$SHARD_NUMBER" - 1)) | |
| # Read in the ALL_REPOS variable based on created shard file | |
| ALL_REPOS=$(cat all_repos_0${SHARD_TO_WORK_ON}) | |
| # Count the repos | |
| ALL_REPOS_COUNT=$(echo "$ALL_REPOS" | awk 'NF' | wc -l | xargs) |
And boom, we’re done.
Summary
For this article, we’ve rewritten a single-threaded, monolithic Action to support multi-threading across Shards, and then updated our bash application code to do the same.
With both of those changes, we’re able to shard our workload across n runners. In this case, I’ve found that any more than 2 runners causes “secondary rate-limit” errors to pop up, so I decided to stick with two. It cuts the run of this huge Action down by about 40%, which is pretty cool.
I do still have a major issue — I’m using a PAT which only has 5k API action tokens per hour, and if I rewrite this Action to be an App, it can both be event-driven (new repo created, immediately update it), and I get 3x as many tokens (and more can be arranged by GitHub!). That’s probably what I’ll have for you next time.
Good luck out there!
kyler