
🔥Let’s Do DevOps: Terraform GitHub Action Targeting from Web Console User Input

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’m helping a team migrate their automation from AWS CodeBuild into GitHub Actions, including Terraform automation. CodeBuild is relatively clunky, but it has something useful that is absolutely critical to this team — you can run a pipeline and target a specific version of your source code — a branch or tag.
Until recently GitHub Actions didn’t support this — they are strong proponents of GitOps, where pure git actions drive all automation, and user input isn’t gathered. However, that has changed!
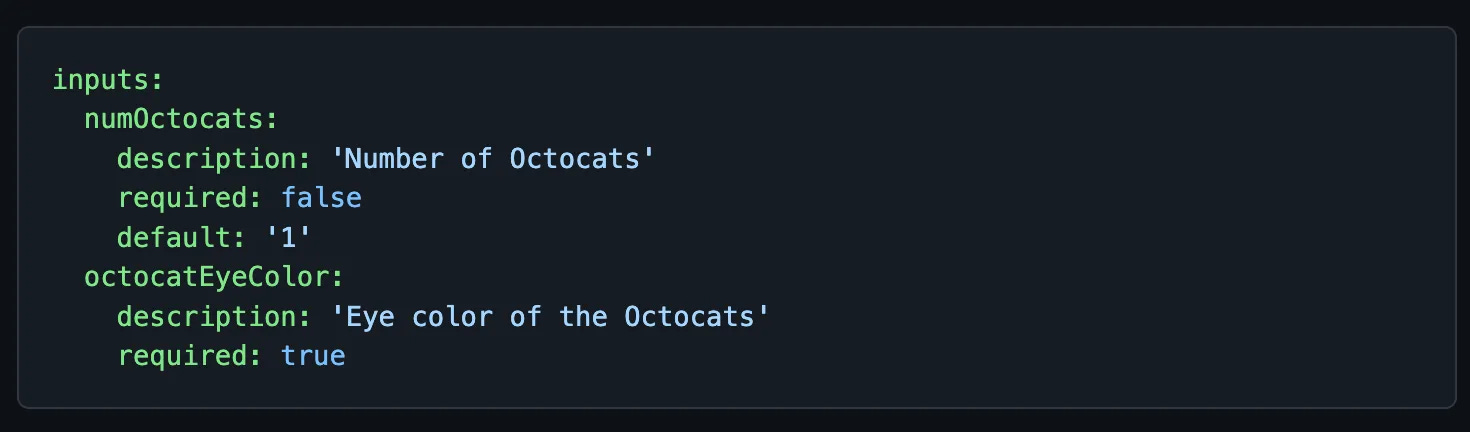
Actions now support both workflow_dispatch (launching an action manually from the web console) and inputs, a way of gathering input from the user when launching an action. We can combine these to have highly dynamic Actions.
Let’s walk through my implementation of a Terraform validation and deploy Action that takes input on launch of:
Branch/tag target
Custom field: Environment and Region of AWS to target
Gathering Action Inputs
The first part of our pipeline names it, and then immediately gathers some inputs. Line 1 names our pipeline. Line 3, on:, is where we’d normally set the triggers for our pipeline, line on_push and filters like the path of files changes.
Here, instead, we set a trigger of workflow_dispatch, which means this action will be triggerable from the github web page console. We set an input called “environment” and add custom fields for description, set it required (line 10), and set some options (line 11). I made up the options on line 11 — put whatever you’d like! This will appear as a required drop-down when launching this pipeline from the web console.
| name: TF Selection | |
| on: | |
| # Permit running manually against any branch | |
| workflow_dispatch: | |
| inputs: | |
| environment: | |
| description: 'Env to run tests against' | |
| type: choice | |
| required: true | |
| options: | |
| - Ue1AccountA | |
| - Ue1AccountB | |
| - Uw1AccountB |
Next we set a global environmental variable, of the version of TF (Terraform) to use. Then we set the permissions for this action. This is required in order to utilize OIDC authentication — we have to access our token to login to our AWS environment.
OIDC is an absolutely amazing security tool, and takes away all the “Can principal X assume role Y across accounts?” questions very well. Learn more here.
| env: | |
| tf_version: 1.2.9 | |
| permissions: | |
| id-token: write | |
| contents: read | |
| repository-projects: read |
Next we start defining our jobs, and create a job called populate_envs. GitHub has excellent standards around a “matrix” of jobs looking up variables specific to this particular job, but I haven’t seen a good solution to this for multiple-choice jobs like this, so I built it myself!
On line 9 we do a run | which means to treat the next section as a single text block, basically an embedded heredoc in YAML syntax.
On line 11, we do a bash case where we check the ${{ inputs.environment }}, which is the name of the input we gathered from our user above, and match it in order to set some useful variables for use in other jobs.
For example, if the input is equal to Ue1AccountA, we set our account_id to 111111111, and we set an assume role for OIDC to gather during the run. Feel free to set any variables here you like! This is pure bash, no special github special sauce.
| jobs: | |
| populate_envs: | |
| name: Populate Envs | |
| runs-on: ubuntu-latest # GitHub Hosted Runners | |
| steps: | |
| - name: Populate Envs | |
| run: | | |
| # Set variables based on run context | |
| case ${{ inputs.environment }} in | |
| Ue1AccountA) | |
| short_region=ue2 | |
| region=us-east-2 | |
| account_id=1111111111 | |
| aws_assume_role_arn=arn:aws:iam::1111111111:role/Role1 | |
| ;; | |
| Ue1AccountB) | |
| short_region=ue1 | |
| region=us-east-1 | |
| account_id=2222222222 | |
| aws_assume_role_arn=arn:aws:iam::2222222222:role/Role2 | |
| ;; | |
| Uw1AccountB) | |
| short_region=uw1 | |
| region=us-west-1 | |
| account_id=2222222222 | |
| aws_assume_role_arn=arn:aws:iam::2222222222:role/Role2 | |
| ;; | |
| esac |
Next we write each of the options we chose to two different places, using the magical tee with -a option (for append). We write the values to $GITHUB_ENV, which is a file that’s read by GitHub before each task within a job. That’ll let these values be used by any task after this one in our job.
We also write it to a file we created called env.vars. That’s also just something I made up — no special github sauce here. And I bet you’re wondering why we’d write those values to a file! Let’s go over it.
On line 7 we define a “cache” using the actions/upload-artifact action. This lets us grab some files and stash them within github, and access them manually, or download them in Actions, which is exactly what we’ll do. Subsequent actions will download this file and read it, making our variables transient to downstream jobs. Pretty cool, huh?
Note that there are lots of ways to pass values to jobs. We could just define some outputs and read them as inputs on the downstream jobs, but I’m doing caching for some other files (that we’ll go over next), so caching made sense to me at the time. Feedback welcome on how what you did makes life easier!
On line 11, check out the name. We mutate the name with our github.run_id, a value that is the same for each downstream job within this Action’s specific run. It’s a great way to keep track of cached files, and not mix them between jobs, something that would definitely happen if we use a static name like “env-cache” only.
| # Write envs to file, must write or variable isn't available in other jobs | |
| echo "short_region=$short_region" | tee -a $GITHUB_ENV env.vars | |
| echo "region=$region" | tee -a $GITHUB_ENV env.vars | |
| echo "account_id=$account_id" | tee -a $GITHUB_ENV env.vars | |
| echo "aws_assume_role_arn=$aws_assume_role_arn" | tee -a $GITHUB_ENV env.vars | |
| - name: Cache Envs | |
| id: cache-envs | |
| uses: actions/upload-artifact@v3 | |
| with: | |
| name: env-cache-${{ github.run_id }} | |
| retention-days: 90 | |
| path: env.vars |
And job done! We have built a matrixed variable set and cached it for consumption downstream. But it’d be lame to stop here. Let’s write a functional terraform pipeline to read that cache and apply some code!
Terraform Plan, Cache, Upload!
The next job we’ll define is terraform plan. This is a great one to run to check if the changes in your code match the environment you’re targeting, and if you do run terraform apply what changes will be made?
First we download our cached env.vars file (line 10) and then read it into our $GITHUB_ENV file. Remember that file? It means that any downstream tasks can grab the values as environmental variables. Now our job knows everything we set in our previous job!
| tf_plan: | |
| name: TF Plan | |
| needs: populate_envs | |
| runs-on: ubuntu-latest | |
| steps: | |
| - name: Checkout Code | |
| uses: actions/checkout@v3 | |
| - name: Download Env Vars | |
| id: download-env-vars | |
| uses: actions/download-artifact@v3 | |
| with: | |
| name: env-cache-${{ github.run_id }} | |
| - name: Read Env Vars | |
| id: read-env-vars | |
| run: | | |
| cat env.vars >> $GITHUB_ENV |
Next we do an OIDC login to AWS using the role we set above (line 1). Then we install terraform of a specific version we set a global variable above (line 7). Then we do our standard init and refresh, but check out line 17, right at the end. We are reading some attributes we computed in our pipeline and passing them to terraform as a variable.
Pretty cool, huh?
| - name: AWS Login | |
| uses: aws-actions/configure-aws-credentials@v1 | |
| with: | |
| role-to-assume: ${{ env.aws_assume_role_arn }} | |
| aws-region: ${{ env.region }} | |
| - uses: hashicorp/setup-terraform@v2.0.0 | |
| with: | |
| terraform_version: ${{ env.tf_version }} | |
| - name: Terraform Init | |
| id: init | |
| run: terraform init -input=false | |
| - name: Terraform Refresh | |
| id: refresh | |
| run: terraform refresh -input=false -var 'region=${{ env.region}}' |
Next we do our terraform plan to generate a change-plan for our code. Note we’re again passing in env.region into our terraform code. Also note we’re setting an -out at the end of line 3. That asks Terraform to generate a binary blob file that contains the list of changes terraform apply can consume downstream.
Then we cache the whole terraform repo. Why the whole repo? What if your auditor wants to see what terraform was applied and by whom? Now you have a record! And since Terraform files are flat ASCII, they’re pretty small.
Well, except for the .terraform folder. That one can get big, because terraform init downloads all the binary Go providers to allow terraform to do useful stuff, like talk to our cloud providers. That’s okay, let’s just skip that directory (line 15). We can always download those files again later, which I venture is both faster and cheaper than caching them here.
| - name: Terraform Plan | |
| id: plan | |
| run: terraform plan -input=false -refresh=false -var 'region=${{ env.region}}' -out tf.plan | |
| - name: Cache Files | |
| id: cache-files | |
| uses: actions/upload-artifact@v3 | |
| with: | |
| name: tf-cache-${{ github.run_id }} | |
| retention-days: 90 | |
| # Grab the entire workspace, but exclude the .terraform folder | |
| # It's large and has provider binaries we can easily download in deploy step | |
| path: | | |
| ${{ github.workspace }}/ | |
| !${{ github.workspace }}/.terraform |
Terraform Apply with Cached Plan
Next we apply our terraform! But we don’t want it to immediately apply the terraform, right? Else, why would we spend all the time generating a change-plan? We want a human to approve that, thank you very much!
Actions is there for us, and we can set an environment (line 5). This environment is wonderful for tracking deployments from many different pipelines — say you have 15 different Actions that all deploy to Prod? Just have them all target the “Prod” environment, and when you find that environment it’ll show all the deployments to it, neatly sorted chronologically! Awesome!
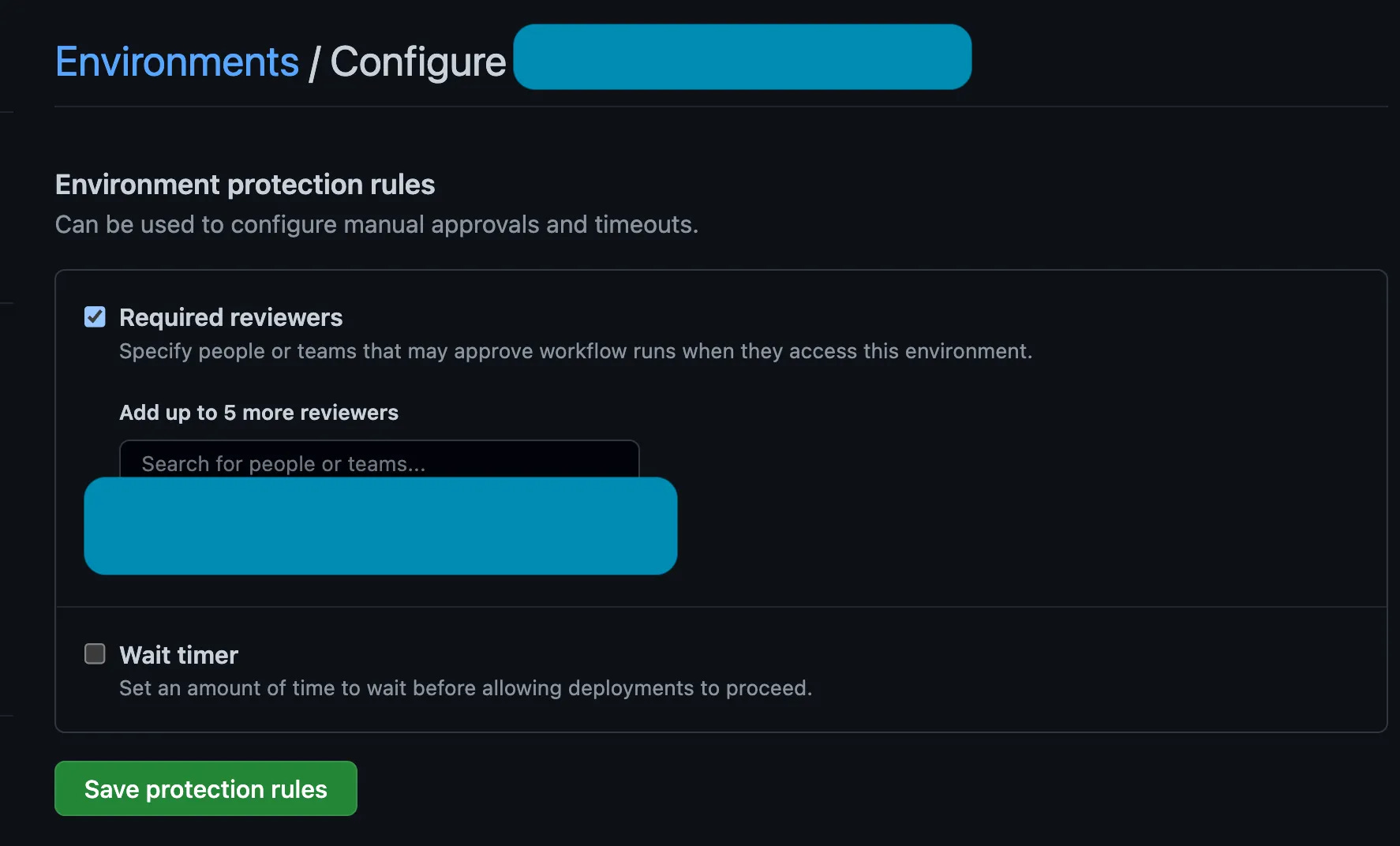
Then we do the same cache download as on the TF Plan job, however we do it twice. First (line 8), we download the terraform cache. This is our terraform code. We need that so we can terraform init and download our binary providers. Then we download (on line 14), the environments variable again — remember, each job could be run on a different machine, and needs to establish all the stuff each time.
| tf_deploy: | |
| name: TF Deploy | |
| needs: tf_plan | |
| runs-on: ubuntu-latest | |
| environment: ${{ inputs.environment }} | |
| steps: | |
| - name: Download Cache | |
| id: download-cache | |
| uses: actions/download-artifact@v3 | |
| with: | |
| name: tf-cache-${{ github.run_id }} | |
| - name: Download Env Vars | |
| id: download-env-vars | |
| uses: actions/download-artifact@v3 | |
| with: | |
| name: env-cache-${{ github.run_id }} | |
| - name: Read Env Vars | |
| id: read-env-vars | |
| run: | | |
| cat env.vars >> $GITHUB_ENV |
Then we do the same OIDC login (line 1), and installing of terraform (line 7). We also terraform init again, which again download the TF binary providers. We (intentionally) didn’t cache them, so we need to download them again.
Then we do a terraform apply. Note we’re not passing it any variables, like the region we had to pass to Refresh and Plan above. That info is already embedded in the file we’re passing it — the tf.plan file.
This has a huge benefit. If your source has changed from when the plan was run, it doesn’t matter at all. Terraform can only apply the exact same plan that you generated earlier and cached. If the environment has drifted for some reason, terraform will fail without making changes and tell you that you should run your Plan again.
| - name: AWS Login | |
| uses: aws-actions/configure-aws-credentials@v1 | |
| with: | |
| role-to-assume: ${{ env.aws_assume_role_arn }} | |
| aws-region: ${{ env.region }} | |
| - uses: hashicorp/setup-terraform@v2.0.0 | |
| with: | |
| terraform_version: ${{ env.tf_version }} | |
| # Required in order to download TF providers since we don't cache those due to size | |
| - name: Terraform Init | |
| id: init | |
| run: terraform init -input=false | |
| - name: Terraform Apply | |
| id: apply | |
| run: terraform apply -input=false tf.plan |
Summary
And we’re done! We built a GitHub Action that takes user input on exactly which branch or tag to deploy, as well as which environment to target our deploys against.
We set custom attributes in a single location, and cached them for downstream jobs to grab. We generated a Terraform change-plan and cached it for a TF apply to run again. We are also using a GitHub Environment to have our Action pause and wait for manual approval.
You can find all the source code here to do it yourself:
GitHub - KyMidd/GitHubActions-ConsoleInputs
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…github.com
Good luck out there!
kyler