
🔥Let’s Do DevOps: Terraform S3 Upload and CloudFront Cache Clearing Automation
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can…

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’m working on a project to write a terraform module to make lambda@edge for http header shimming (which is like, so cool) really easy. It’s like, so cool, and I want to make it super easy to implement.
However, this article isn’t about that. In the course of researching and labbing that up, I had to keep clearing the CloudFront cache from the console. And that was annoying, because everything else I can do with terraform and curl. Surely Terraform has a method of clearing a cache.
Surely there’s a way to clear the CloudFront cache from Terraform…
Turns out, no
Which I think is so strange! Yeah, it’s an unusual use case, but surely we could have a resource that permits tainting the cache or triggering this action some other way, like an object that clears the cache on a new version push. But nothing like that exists in the AWS provider.
And it’d be really cool if it did, right? You could use Terraform as your entire web CI/CD — have it grab your website, push to S3, clear CloudFront cache, all really quickly and easily.
And suddenly my lambda@edge module project became “how can I get Terraform to auto-clear the CloudFront cache when I push a new web page up?”
We’ll talk about each important piece inline, and also link to a github repo at the end of this article if you want to deploy all of it and play with it yourself. It makes deploying a simple web page with CloudFront front-end take like 2 minutes, which is pretty cool by itself!
S3 + CloudFront
Before we start automating, let’s talk about the services we’re discussing.
S3 is a bucket for storing files. Within each S3 bucket, you can put files and folders, both known as “objects”. S3 subscribes to the *nix idea that files and folders are both just objects.
S3 integrates with so👏 many 👏other👏 services 👏. S3 can directly serve a website itself, which is pretty cool, but you have a really limited ability to set http header flags, or caching, or do deep security integrations and heuristic blocking.
To do those great things, you need CloudFront. CloudFront is a global CDN, which means it operates a distributed network of caching nodes that will fetch data from your bucket origin one time, then cache it for a long time, so if your website is hit 10k times, the cache is only populated once. This can save you a lot of money.
And as mentioned above, CloudFront does a ton of cool things:
Origin obfuscation — You probably don’t want random internet folks to know the name of the S3 bucket you’re serving data from. Or even that you’re serving data from an S3 bucket. CloudFront can do that.
Global caching — You pay for data xfer out of AWS, which means every time someone visits your website, you pay a little cost for the transfer. If your site is popular, that can really add up! CloudFront also costs for data xfer out of AWS, but it’s far reduced from S3.
WAF Integration — AWS’s WAF (Web Application Firewall) service integrates with CloudFront, meaning you can setup blocklists of bad IPs, as well as deep inspection of traffic to block some exploits before your servers are patched. You want WAF turned on, and CloudFront makes that easy.
So much more!
Serving a Website from S3 via CloudFront
To serve a website or file from S3 to users via CloudFront, we first need to upload the object to S3. This is possible to do manually, but Terraform supports this as well.
Then we put an IAM policy on our S3 bucket that grants the specific CloudFront distribution OAI (Original Access Identity) user to get to that content. That means that only that specific CloudFront distribution can get to our files — folks can’t even access the S3 bucket directly, which is what we want. We don’t want anyone to bypass our CloudFront/WAF security, right?
Then we configure our CloudFront distribution to use our S3 bucket as the origin it’s fetching from. It also does some other cool tricks, like automatic redirection from HTTP to HTTPS, and a bunch of other stuff — read the Terraform code for the full coolness here.
The trick here is that once this is setup and working, on the first time accessing the cloudfront distribution, it will do what’s called a “cache miss”, meaning that data is not yet cached. It will hold up the http connection between the client and cloudfront, and fetch the data from the origin in the meantime. Cloudfront talks to S3, grabs the data, creates a cache, and then serves the request. This all happens super duper fast.
Next time someone requests the data, the cache is populated, and the data is served immediately, without consulting S3.
The problem arises when we update S3 to have a new version of the file, but CloudFront isn’t natively able to monitor that, and happily continues serving the old version. This can be really frustrating when you don’t realize what’s happening or why!
To fix this, we create what’s called a “cache invalidation” that basically instructs CloudFront to dump its cache for a particular URI (folder path from the root) or to just clear the whole thing (/*).
What Terraform Can Do
Terraform is excellent at creating and managing infrastructure. I ❤ Terraform. It can create the S3, bucket policy, CloudFront distribution, all that jazz, and sync them up.
I was surprised to learn it can even grab a file, check the file’s hash using MD5, and if the file has changed, upload the new version to an S3 bucket. Which is a really cool atomic transaction that I didn’t realize Terraform would be able to do.
However, as mentioned above, Terraform can’t do that single last piece — clearing the CloudFront cache.
So for our entirely-Terraform-based web CI/CD, we can deploy our new version of our file to S3, but not clear CloudFront, so the old version of the file would keep getting served. Booooo.
But terraform is flexible. Let’s hack something together.
Using Terraform Properly
Let’s start with our website. I’m using a simple web HTML doc for fun — it’s cool to see this deployed to cloudfront in like 2 minutes.
| <HTML> | |
| <HEAD> | |
| <TITLE>Website for testing CloudFront</TITLE> | |
| </HEAD> | |
| <BODY BGCOLOR="FFFFFF"> | |
| <HR> | |
| <H1>Congratulations!</H1> | |
| Your website appears to be working <BR> | |
| You are now an expert at: | |
| <ul> | |
| <li>S3</li> | |
| <li>CloudFront</li> | |
| <li>Terraform</li> | |
| <li>Lambda@Edge</li> | |
| </ul> | |
| <BR> | |
| Okay, well at least you're smarter than you were yesterday.<br> | |
| And isn't that the goal at the end of the day anyway? | |
| <HR> | |
| </BODY> | |
| </HTML> |
And then we can tell Terraform to monitor that file, and if its etag changes (we’re calculating this with a local filemd5() call), it triggers Terraform to upload the new file.
| resource "aws_s3_object" "website" { | |
| bucket = aws_s3_bucket.aws_s3_bucket.id | |
| key = "index.html" | |
| acl = "private" | |
| source = "./website/index.html" | |
| etag = filemd5("./website/index.html") | |
| content_type = "text/html" | |
| } |
Okay, so far so good — we have a way to store our local web file, then terraform will notice any changes and deploy them to S3. Sweet.
But now we need to do something Terraform… can’t. Let’s hack some terraform stuff together.
Terraform Hacking!
First of all, it’s not strictly true that Terraform can’t clear the CloudFront cache. It is true that there is no native resource or data call that can do it. However, Terraform can wrap other tools, including the CLI. Doing a CLI call from Terraform uses the local-exec provisioner that can live within resources to run commands on a resource creation.
| provisioner "local-exec" { | |
| command = "aws cloudfront create-invalidation --distribution-id ${var.cf_id} --paths '/*'" | |
| } |
So we could put that in the aws_s3_object resource, but there’s a problem. The object isn’t recreated, it’s only updated, within terraform. The local-exec provisioner runs only one time — when the resource is created. So we could clear the cache 1 time — the first time.
That doesn’t get us anywhere.
I can create a null_resource to store that commands, and then find some way to rebuild it though! And maybe a depends_on that would check an output from a different resource and trigger a rebuild? Something like this:
| resource "null_resource" "invalidate_cf_cache" { | |
| provisioner "local-exec" { | |
| command = "aws cloudfront create-invalidation --distribution-id ${var.cf_id} --paths '/*'" | |
| } | |
| depends_on = [ | |
| aws_s3_object.website.etag, | |
| ] | |
| } |
However, this isn’t valid. depends_on doesn’t operate after resource attributes are read, it’s used only for provisioning ordering, and can only reference a whole resource or module. So that’s a no-go.
But there’s hope! The null_resource supports the concept of triggers that are able to map directly to an output, and if the resource attribute changes, trigger a rebuild of the null_resource. That is our golden ticket!

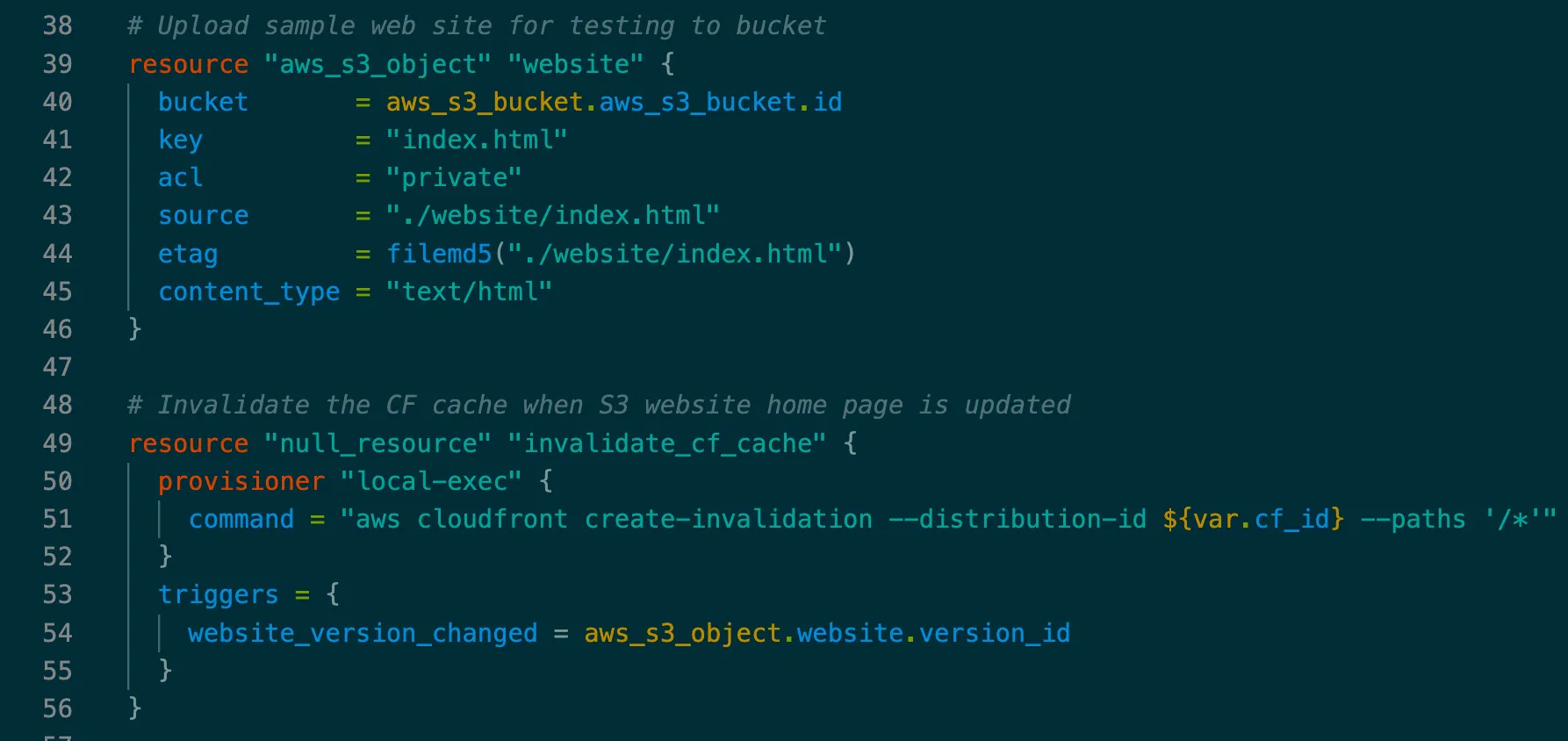
Here’s our final and working solution! We use a null_resource that only operates locally during a Terraform run, and within it the AWS CLI commands to invalidate the whole CloudFront distribution.
And we set a trigger of the website update to map to the version_id attribute of our website upload resource. That means when a new version of the website is pushed to S3, that version will change, triggering this resource to recreate, which will create a CloudFront invalidation.
| resource "null_resource" "invalidate_cf_cache" { | |
| provisioner "local-exec" { | |
| command = "aws cloudfront create-invalidation --distribution-id ${var.cf_id} --paths '/*'" | |
| } | |
| triggers = { | |
| website_version_changed = aws_s3_object.website.version_id | |
| } | |
| } |
Profit
The whole process takes about 2 minutes to deploy the first time. Then, when the website is updated, it takes about 2 seconds of Terraform time to issue the invalidation request, and CloudFront invalidates the cache in the next 30–60 seconds or so.
This is a simple web deploy CI/CD, but illustrates some cool non-native Terraform functionality that can be hacked in. Terraform rules.
Here’s all the code to build it yourself:
GitHub - KyMidd/Terraform_AutoInvalidateCloudFront
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…github.com
Good luck out there!
kyler