
🔥Writing Dozens of Tools to Migrate an Enterprise from BitBucket to GitHub

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
These blog normally zooms in on particular technologies or use cases, but today we’re going to zoom out. Way, way out. I was recently (well, 6 months ago), to migrate an enterprise from an internal Stash/BitBucket server to a GitHub Organization. Full stop, good luck!
That project is nearly complete. As part of gathering information, preparing the new GitHub tenant, and executing the migration, I’ve had the opportunity to write dozens of bespoke tools. These tools are intended to gather information, build reference files that downstream tools will use, or to directly update settings or copy code and other repos. They create PRs in GitHub, they update Jenkins pipelines, they read and set settings in Jenkins, GitHub, and BitBucket.
As a collection, they are what enables this very large project to move forward. Let’s talk about some of the tools I remember writing (there are surely more I don’t!) and what they do! 🚀
Tooling Note: I Build My Own
Note for folks reading — there are ocassionaly tools available on these platforms or in public that could gather this information for us. However, I am reticent to use external tooling — I don’t know perfectly how it works, I don’t trust it fully, and it’s often not as customizable as writing my own tools.
Therefore, I write my own tools whenever possible.
Who Are The Active Users?
The first question of most migrations is licensing. It takes a long time to purchase things, and can be expensive, so we want accurate counts for licenses. So, a simple question — Which users (and how many) are active in our projects on our internal BitBucket server?
We don’t want to buy too many licenses, and we are only first moving one division to GitHub. So we need to see how many users are “active”. That “active” is hard to define. Have they opened a PR? Commented on a PR? Reviewed a PR? Then they’re “active”. BitBucket doesn’t have an easy report for that, but I did find it displays that information in its APIs for each PR.
So the solution — let’s read a list of BitBucket Projects that are part of our migration, then read each repo, then in each repo, read each PR’s attributes, which include those active metrics. Then
The tool is here: https://gist.github.com/KyMidd/9a7481ef1be2f7d639b36b6d785e16b0
The meat of it is in the loop here. We read each project, then read each repo, then query the author and reviewer (which includes all votes on any PR) for the last 1k PRs. We output all users to a file. It will of course include (mostly) duplicates, but the sort and uniq tool give us a workable list of folks. At least close enough for a human to read and count for licensing purposes.
| for PROJECT in $(echo $EHR_RELATED_STASH_PROJECTS); do | |
| echo "💥 Working on project $PROJECT" | |
| # Find slug of all repos in a project | |
| unset PROJECT_REPOS | |
| PROJECT_REPOS=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects/$PROJECT/repos\?limit\=$PR_LIMIT | jq -r '.values[].slug') | |
| # Iterate over each repo to find all PRs, read limit from var | |
| for REPO in $(echo $PROJECT_REPOS); do | |
| echo "Working on repo $REPO" | |
| unset AUTHOR_USER_NAMES | |
| unset REVIEWER_USER_NAMES | |
| AUTHOR_USER_NAMES=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects/$PROJECT/repos/$REPO/pull-requests\?state\=ALL\&limit\=$USER_LIMIT | jq -r '.values[].author.user.name' | sort | uniq) | |
| REVIEWER_USER_NAMES=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects/$PROJECT/repos/$REPO/pull-requests\?state\=ALL\&limit\=$USER_LIMIT | jq -r '.values[].reviewers[].user.name' | sort | uniq) | |
| echo $AUTHOR_USER_NAMES | tr " " "\n" >> users | |
| echo $REVIEWER_USER_NAMES | tr " " "\n" >> users | |
| done | |
| done | |
| # Sort, uniq | |
| cat users | sort | uniq > users_sorted |
Which Collections Should Go First?
We organize our repos by Collection, a bucket organized around code function. Which Collections should go first?
Again, an easy option here is to talk to people 🤢🤢
Or we could crawl over all the Project Collections in Stash and count how many PRs they have open. This is an incredibly rough metric — these PRs could have been open for months or years. However, I don’t care to have guaranteed accurate information here. Rather, I’m seeking a rough guide for who should be migrated first (those collections that aren’t “active”, and those which we should avoid for now “not active”).
So we crawl over every project in stash, then iterate over each repo, and count the PRs in an open state in each repo. We aggregate the PR counts per Project, and write it to a CSV so I can sort it in excel.
| # Find all project keys | |
| STASH_PROJECT_KEYS=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects\?limit\=1000 $| jq -r ".values[].key") | |
| # Iterate over list of repos, generate repo clone urls | |
| ### Loop over every repo in environment | |
| while IFS=$'\n' read -r PROJECT_KEY; do | |
| # Set counter var | |
| OPEN_PR_COUNT=0 | |
| echo "X Searching project: $PROJECT_KEY" | |
| # Find all repos in project | |
| ALL_REPOS_IN_PROJECT=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects/$PROJECT_KEY/repos\?limit\=1000 $| jq -r '.values[].slug') | |
| while IFS=$'\n' read -r REPO_NAME; do | |
| #echo "- Searching repo: $REPO_NAME" | |
| # Find count of open PRs in repo | |
| REPO_OPEN_PR_COUNT=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects/$PROJECT_KEY/repos/$REPO_NAME/pull-requests $| jq -r .size) | |
| echo "- Repo $REPO_NAME has $REPO_OPEN_PR_COUNT open PRs" | |
| # Increment counter var | |
| ((OPEN_PR_COUNT=OPEN_PR_COUNT+REPO_OPEN_PR_COUNT)) | |
| done <<< "$ALL_REPOS_IN_PROJECT" | |
| echo "$PROJECT_KEY has $OPEN_PR_COUNT open PRs" | |
| echo "$PROJECT_KEY,$OPEN_PR_COUNT" >> project_open_prs.csv | |
| done <<< "$STASH_PROJECT_KEYS" |
Again, not a super accurate measure, but enough to build a skeleton schedule and present to the teams for them to object or agree.
Copy The Git Repo to GitHub
We first intended to copy all the code from Bitbucket to GitHub with a tool we wrote. I did my best to write a tool, including some incredibly cool features. We eventually gave up on that effort though — the scope of it was greater than expected. Almost all the code for a git repo is built into the git tree — the commits, tags, branches, etc.
However, BitBucket and GitHub are entirely different for the metadata around the git repo — Pull Request standards, comments on commits, the rules around commits (GitHub doesn’t permit commit messages that are blank, as BitBucket does), and we decided to give up.
We purchased a tool from GitHub proper — that tool works pretty well. However, it’s not as comprehensive as we’d hoped, and it does occasionally run into issues, just like our code used to.
In retrospect, I wish I’d continued to build out this code.
My code, which you can find here: https://gist.github.com/KyMidd/5babbba7821d675916a2ca1c30bb4414
Here’s a snippet of it that reads a Project from from BitBucket, finds the clone information, finds the clone URL, clones the repo, and attempts to push the repo to a newly created GitHub repo without modification. Right after this snippet, we ready any error messages and attempt to fix them automatically.
| # Grab all repo clone values | |
| getRepoCloneValues=$(cat project_repos_raw | jq --raw-output --arg repo "$repo" ' | |
| .values[] | |
| | select( .name | contains($repo)).links.clone[] | |
| | select( .name | contains("ssh")) | .href') | |
| # Select first repo clone value if there are multiple | |
| IFS=';' read -r stashRepoUrl string <<< "$getRepoCloneValues" | |
| # Clone old repo | |
| git clone --mirror $stashRepoUrl $repo | |
| # Change context into folder | |
| cd $repo | |
| # Attempt push trap results | |
| echo "Attempting git push --mirror without any modifications" | |
| gitPushResults= | |
| gitPushResults=$(git push --mirror https://oauth2:$GITHUB_TOKEN@github.com/$github_project_name/$github_repo_name.git --porcelain 2>&1) |
This tool reads a file in the same repo, which lists a series of Bitbucket projects. The tool gathers a list of all repos in that project, then iteratively clones each repo to local, creates a corresponding repo in GitHub, then writes a new .git configuration to point at the github origin, and pushes to GitHub.
I also added the ability for it to automatically detect when files are too large for GitHub (GitHub limits files to 100MB, BitBucket doesn’t), and use the bfd tool to rewrite the git history to use lfs (Large File Storage), a github technology for storing pointer files in the git tree to point at external large files. That part is incredibly cool, and doesn’t exist in the GitHub tool we purchased — it simply skips those files.
It’s also capable of rewriting commit messages where they are too long for GitHub (BitBucket again permits longer messages) into the git tree on the fly, in an entirely automated way.
We used it to migrate more than 500 repos that were legacy and kept for archive purposes.
The tool GitHub provided is here (but is permission locked).
Create the Exporter File
In order to tell our GitHub exporter tool which repos to package up for import into github, it requires a file. The file looks like this:
PROJ1,reposlug1
PROJ1,reposlug2
PROJ2,reposlug3
PROJ3,reposlug4Creating that file for a dozen or so BitBucket Projects at a time is a bit of a pain, so I wrote a little bash loop that does it for me:
| for PROJECT_CODE in PROJ1 PROJ2 PROJ3; do | |
| REPOS=$(curl -s --user $STASH_USER:$STASH_PASS "https://$STASH_URL/rest/api/1.0/projects/$PROJECT_CODE/repos?limit=1000" | jq -r '.values[].name') | |
| while IFS=$'\n' read -r REPO_NAME; do | |
| echo $PROJECT_CODE,$REPO_NAME | |
| done <<< "$REPOS" | |
| done |
This is also a great skeleton when I need to run one of the other tools on this page against multiple collections in sequence. Rather than updating my tools to accept a list of projects, I just run this in the above little for loop and it does the same thing. Tomato, tomato.
Create Hundreds of GitHub Teams
Our repos are organized into “collections”, which roughly break down to a bunch of repos managed together. And within each collection, we have several teams. Those teams are always the same organization. They manage that collection’s databases, UI, testing, services, things like that.
Those groups are assigned different permissions levels for that collection’s repos. We didn’t want to change that structure — as much as possible, large projects like this should change as little as possible. So we need to create a BUNCH of teams in GitHub.
| # Set child team name | |
| unset TEAMNAME | |
| TEAMNAME="$PROJECT"$2 | |
| echo Child team name will be $TEAMNAME | |
| # Check if exist | |
| unset CURL | |
| CURL=$(curl -s \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN" \ | |
| https://api.github.com/orgs/$ORG/teams/$TEAMNAME) | |
| if [[ $(echo "$CURL" | grep "Not Found" | wc -l) -eq 1 ]]; then | |
| echo "Team does not exist, create" | |
| echo Creating team "$TEAMNAME" | |
| unset CURL | |
| CURL=$(curl -s \ | |
| -X POST \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN" \ | |
| https://api.github.com/orgs/$ORG/teams \ | |
| -d "{\"name\":\"$TEAMNAME\",\"privacy\":\"closed\",\"parent_team_id\":$PARENT_TEAM_ID}" 2>&1) |
We again read the list of collections from the master-doc, and then for each collection name, we create a parent team. For instance, if the collection is named Foo, we create a team named Foo in GitHub. Then we lookup that team’s ID, and create several child names that are in charge of particular aspects of that collection, like database and UI. Those teams are created as children of the parent for easy organizing.
The full code is here: https://gist.github.com/KyMidd/ef67eefb07a502e43c4cd506742eb858
We created about 250 teams using this tool.
“What’s Your GitHub User Name?” Automation
This one, like most of these questions, seems pretty simple at first. BitBucket uses a windows active directory username to identify users, and that’s what their git information is tied to. GitHub uses a GitHub user ID, which doesn’t follow any standard if you permit your users to create their own.
We could ask each user to provide their github user ID, but that sounded like a great deal of talking to humans, which I wasn’t thrilled about 🤢
Instead of that, I decided to read that list of active users from earlier — remember when we read the last 1k PRs for every repo in every project to find all the users?
I needed to export all the user’s email addresses and save them, so I wrote this snippet. It reads a list of users (with 1 username per line), looks up the user and prints their email address.
| # Remember to export $STASH_PASS before running | |
| if [[ -z $STASH_PASS ]]; then | |
| echo "Remember to export STASH_PASS=(your password)" | |
| exit 0 | |
| fi | |
| # Grab info from source | |
| curl -s --user $STASH_USER:$STASH_PASS https://stash.hq.practicefusion.com/rest/api/1.0/admin/users\?limit\=1000 -o stashusers.json | |
| while IFS="," read -r USERNAME | |
| do | |
| cat stashusers.json | jq -r ".values[] | select(.slug==\"$USERNAME\") | .emailAddress" | |
| done < users |
Our users are required to use their work email address for their GitHub user, and that name almost always matches their internal username. For example, kyler.middleton@(work email.com) to a username of kyler.middleton or kmiddleton. With that assumption in mine, we can map GitHub users in our Org’s email addresses to our BitBucket user’s usernames. Boom, that amount of shared information allows us to create a map.
Populate All The Team Members!
We created about 250 teams in GitHub using a tool above, but those teams are empty. Well, they were created with me as a member, which I had to remedy — I don’t want to get all the emails for every collection of repos, that would drive me crazy.
But once I removed myself, those teams are all empty. I initially wanted to just elect a “maintainer” for each team, and tell them they’re in charge of populating the teams with users. But that group pushed back, and asked me a catnip question — is there a way to automatically populate these teams?
Well, not with any tool we currently have… but I bet I can remedy that! 🚀
Our master doc of repo collections also contains the member’s BitBucket names that should belong to those groups. Even if it didn’t, I could probably scrape the BitBucket API for group membership — the names are predictably constructed, so that would also have worked.
But remember, the names in BitBucket and the names in GitHub are entirely different. We have to iterate over every collection, constructing the team names as we go, then check our master doc for team membership, then lookup the name of the member in our Bitbucket/GitHub map, then add that user to the GitHub team.
The entire script is here: https://gist.github.com/KyMidd/6e9d720598c3cfda7342b88bd7fddd59
| while IFS="," read -r GITHUB_USERNAME HQ_USERNAME | |
| do | |
| # Normalize casing | |
| GITHUB_USERNAME=$(echo $GITHUB_USERNAME | tr '[A-Z]' '[a-z]') | |
| HQ_USERNAME=$(echo $HQ_USERNAME | tr '[A-Z]' '[a-z]') | |
| done < github_user_and_hq_username.csv | |
| if [ -z "$GITHUB_USERNAME" ]; then | |
| echo "☠️ GitHub username not found" | |
| else | |
| echo "- GitHub username for this user is: $GITHUB_USERNAME" | |
| # Add user to team | |
| unset CURL | |
| CURL=$(curl -s \ | |
| -X PUT \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN" \ | |
| https://api.github.com/orgs/$ORG/teams/$TEAM_SLUG/memberships/$GITHUB_USERNAME \ | |
| -d '{"role":"maintainer"}' 2>&1) |
Using this tool we were able to populate ~250 GitHub teams with ~100 members, in about 750 unique pairings.
GitHub Default Branch and Repo Name Casing Fixes
The GitHub-provided tool to migrate repos from our internal BitBucket to our GitHub tenant works remarkably well, but it isn’t perfect. It loses the default branch for each repo, which caused a surprising amount of chaos, and it loses all the casing for names. So, for instance, ThisAwesomeTool becomes thisawesometool, which is much harder for humans to read.
Our default branch is almost always develop, so solving that problem was easy-ish. GitHub lets us read a repo’s branches as metadata using the REST API, so I iterated over all our freshly migrated repos, and checked if the develop branch exists. If yes, we set is as the default. If not, we skip updating it. I figure that’s liable to generate many fewer error messages than attempting to update every repo to develop and having maybe 25% of them fail each time.
| # Check which branches exist | |
| BRANCHES=$(curl -s \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN" \ | |
| https://api.github.com/repos/$GH_ORG/$GH_REPO/branches | jq -r '.[].name') | |
| # If branch exists, set as default | |
| if [[ $(echo "$BRANCHES" | grep -E "develop") ]]; then | |
| echo "The develop branch exists" | |
| # Check current default branch | |
| REPO_DEFAULT_BRANCH=$(curl -s \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| https://api.github.com/repos/$GH_ORG/$GH_REPO | jq -r '.default_branch') | |
| if [[ "$REPO_DEFAULT_BRANCH" == 'develop' ]]; then | |
| echo "Develop is already the default branch, making no changes" | |
| else | |
| echo "Develop isn't the default branch, updating" | |
| UPDATE_DEFAULT_BRANCH=$(curl -s \ | |
| -X PATCH \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| https://api.github.com/repos/$GH_ORG/$GH_REPO \ | |
| -d '{"default_branch":"develop"}') | |
| fi | |
| else | |
| echo "Develop doesn't exist, skip updating default branch" | |
| fi |
And remember the capitalization problem? I can’t easy computer-solve where casing should be in each repo, but the characters are the same! So I can check each repo’s name in github, and then lookup that “slug” (lower-case unique ID) in Stash that matches, then find the BitBucket repo “name”, which is the same string, but with proper casing. Then I can update the GitHub repo to match that name.
| # Fetch stash repo correct spelling, if different from github name, correct name on github | |
| # Fetch correct capitalization of name from stash | |
| REPO_CORRECT_CAPS=$(curl -s --user $STASH_USER:$STASH_PASS https://$STASH_URL/rest/api/1.0/projects/$STASH_PROJECT_KEY/repos/$GH_REPO | jq -r .name) | |
| echo "Correcting casing of repo names to match stash" | |
| CORRECT_REPO_CASING=$(curl -s \ | |
| -X PATCH \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| https://api.github.com/repos/$GH_ORG/$GH_REPO \ | |
| -d "{\"name\":\"$REPO_CORRECT_CAPS\"}") |
The REST call looks funny — we’re updating a repo using its name… to update its name.
We’ve corrected about 200 repos so far using this tool, and our humans are much happier reading repos that are capitalized correctly.
Stage Actions and CODEOWNERS files in Thousands of Repos
I’ve complained about this before, and I’ll complain about it again. In the BitBucket world, if you have an Action or Extension that should exist in every repo, you’re able to enable it at the Tenant or Project level. You do that once, the settings are all the same, and it’s absolutely amazing and works perfectly.
GitHub works in a much more idiosyncratic way — each repo is an island. They are technically organized into Organizations and Enterprises, and the permissions and some settings flow down to Repos, but not much else. For instance, we have some Actions that are required in each Repo to validate commits and test code. The solution?
Update the files in 👏 every 👏 single 👏 repo 👏.
Well that’s weird and alarming.
Surely GitHub has a great tool that can do that for us? Nope. “Go build it yourself”. Fine, so I did.
Because this is an internal tool, we can customize the heck out of it, so we did. Each repo we create belongs to a collection. That collection means a specific set of teams should be assigned permissions. Also each repo requires different Actions from our group of internal Actions.
Since that info isn’t always obvious (repo names don’t contain all that information), we need to set some metadata somehow. I could potentially run this tool many times, setting those attributes each time. But that’s a bummer. Easier is to create a metadata doc that contains flags for each of those customizable attributes.
I created a CSV-like (I say -like, because CSVs don’t support blank lines and commented out lines, which I added to my CSV-ish file) file that contains a repo name, then a series of flags. It looks like this:
| GH_REPO_NAME,DEPLOY_COMMIT_CHECKER,DEPLOY_ANY_VALIDATE,DEPLOY_MERGE_COMMIT_NOTIFY,CODEOWNERS_TEAM_SLUG,COLLECTION_MIGRATION_TICKET | |
| # CollectionName | |
| REPO1,true,true,true,CollectionName,DO-12345 | |
| REPO2,true,false,false,CollectionName,DO-12345 | |
| REPO3,true,false,true,CollectionName,DO-12345 |
My tool iterates over this file, and in the context of each repo (GH_REPO_NAME), it checks whether we should deploy an Action called the Commit Checker (DEPLOY_COMMIT_CHECKER boolean), deploy the Action called the Any-Validate (DEPLOY_ANY_VALIDATE), etc. For each repo, we can set n values that customize how the Actions and CODEOWNER are deployed.
| # If we've made any changes, create branch, add files, push | |
| if [ $MADE_CHANGE = true ]; then | |
| # Checkout local branch | |
| git checkout -b feature/${COLLECTION_MIGRATION_TICKET}-Create-GitHubActions-and-CODEOWNERS | |
| # Add files to git | |
| git add .github/workflows/_PfGitCommitChecker.yml &>/dev/null | |
| git add .github/workflows/ActionPRValidate_AnyJobRun.yaml &>/dev/null | |
| git add .github/workflows/MergeCommitNotify.yml &>/dev/null | |
| git add CODEOWNERS &>/dev/null | |
| # Commit changes | |
| COMMIT=$(git commit -m "${COLLECTION_MIGRATION_TICKET} Create GitHub Actions and CODEOWNERS") | |
| if [[ $(echo "$COMMIT" | grep 'nothing to commit' | wc -l | awk 'NF') -eq 1 ]] ; then | |
| echo "No changes, nothing to commit" | |
| else | |
| # Changes detected, print commit info and do PR | |
| echo "$COMMIT" |
Once it decides that, it knows which files to copy over.
The CODEOWNERS file is a little more complicated. It needs to set the “codeowners” for each repo, which means it needs to target the appropriate teams, of which there can be multiple. Different repo types have different logic, so we start there with the repo name to identify the repo type, then based on that type, set the CODEOWNERS string to target the different names of teams using their lower-cased name/slug in github.
Then as a last step, we use sed to update a file in place to replace a placeholder string with the real value that should exist for the CODEOWNERS. Voilà, a valid and specific-to-this-repo CODEOWNERS file.
| if [[ $GH_REPO_NAME == *"database"* ]]; then | |
| # CODEOWNERS should contain all 4 leads groups for this project | |
| CODEOWNERS="@$GH_ORG/${SERVICES_LEADS_TEAM_SLUG} @$GH_ORG/${TEST_LEADS_TEAM_SLUG} @$GH_ORG/${UI_LEADS_TEAM_SLUG} @$GH_ORG/${DATA_LEADS_TEAM_SLUG}" | |
| #echo "database" | |
| # If endpoint, api, or apiendpoint ends repo name | |
| elif [[ $GH_REPO_NAME == *"endpoint" ]] || [[ $GH_REPO_NAME == *"api" ]] || [[ $GH_REPO_NAME == *"apiendpoint" ]]; then | |
| # CODEOWNERS should contain ServiceLeads, UILeads, TestLeads (but not DataLeads) | |
| CODEOWNERS="@$GH_ORG/${SERVICES_LEADS_TEAM_SLUG} @$GH_ORG/${TEST_LEADS_TEAM_SLUG} @$GH_ORG/${UI_LEADS_TEAM_SLUG}" | |
| #echo "api/endpoint" | |
| # All others assumed that ServicesLeads are owners | |
| else | |
| # CODEOWNERS should contain ServicesLeads only | |
| CODEOWNERS="@$GH_ORG/${SERVICES_LEADS_TEAM_SLUG}" | |
| #echo "services owned" | |
| fi | |
| # Sed in CODEOWNERS var to file | |
| sed -i '' "s#PF_CODEOWNER#$CODEOWNERS#g" CODEOWNERS |
The entire code is here: https://gist.github.com/KyMidd/83cd77cab8588e0c7cb3cfb9c62b7d38
We’ve created ~400 PRs to deploy ~1k files in our tenant so far, and it’ll be well over 1k PRs to deploy ~5k files when we’re done.
Dear GitHub — wouldn’t it be easier if we could set this at the Org or Enterprise level? 🙃
Update our Jenkins to Point at the New Code Source Location
When we initially scoped this project out, we decided we wanted to make it as atomic as possible. For us, that means to separate moving our code location to a different place from converting our build automation to GitHub. Jenkins does an incredible job for us, it’s open source, it’s amazing, and we didn’t want to create Actions as we went — they already exist in Jenkins, let’s use those.
The first problem presented itself right away — our Jenkins is INSIDE our company network. GitHub is OUTSIDE our company network. You see what I’m getting at here? We looked at creating an API gateway to bridge webhooks from GitHub to Jenkins to trigger jobs, but eventually threw it all away.
Rather, we can run Actions from inside our network on builders we host ourselves. That compute can talk directly to Jenkins without us having to expose Jenkins in any way. Sounds easier, so we did it. A full write-up of how we use Actions to send commitNotification calls to Jenkins and then track the jobs that are spun off to see which ones are linked to the commit we’re validating is here:
Let’s Do DevOps: GitHub to Jenkins Custom Integration using Actions, Bash, Curl for API Hacking
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots…kymidd.medium.com
But now we need to update Jenkins. Our code is in a new place, we need to tell Jenkins. I initially attempted to hook in using the REST API. Jenkins itself (Jenkins core) has amazing APIs. I can update and call anything I need, it’s amazing.
However, Jenkins is build to be highly modular and pluggable, and even core functionality (clone a repo to build the code) is part of a module, and those modules are very hit or miss with API support. Our particular modules didn’t have the API support I need to update their configuration via API call. Lame!
However, we can issue a call to Jenkins to download ALL the job’s config as an xml file. I don’t love that — I’ve become proficient at using jq to mess around with javascript files, and I don’t love working with xml.
| # Download the job XML | |
| echo "- Downloading job xml/${job}_original.xml" | |
| #rm xml/${job}_original.xml | |
| curl -s -u "$JENKINS_USERNAME:$api_token" -X GET "https://$JENKINS_URL/job/${job}/config.xml" > xml/${job}_original.xml | |
| # Check the git source | |
| if [[ $(cat xml/${job}_original.xml | yq -p xml .project.scm.userRemoteConfigs | grep url) == *"github"* ]]; then | |
| echo "✅ The pipeline already points at github, and requires no changes" | |
| else | |
| # Changes needed | |
| echo "🚧 Pipeline needs changes" |
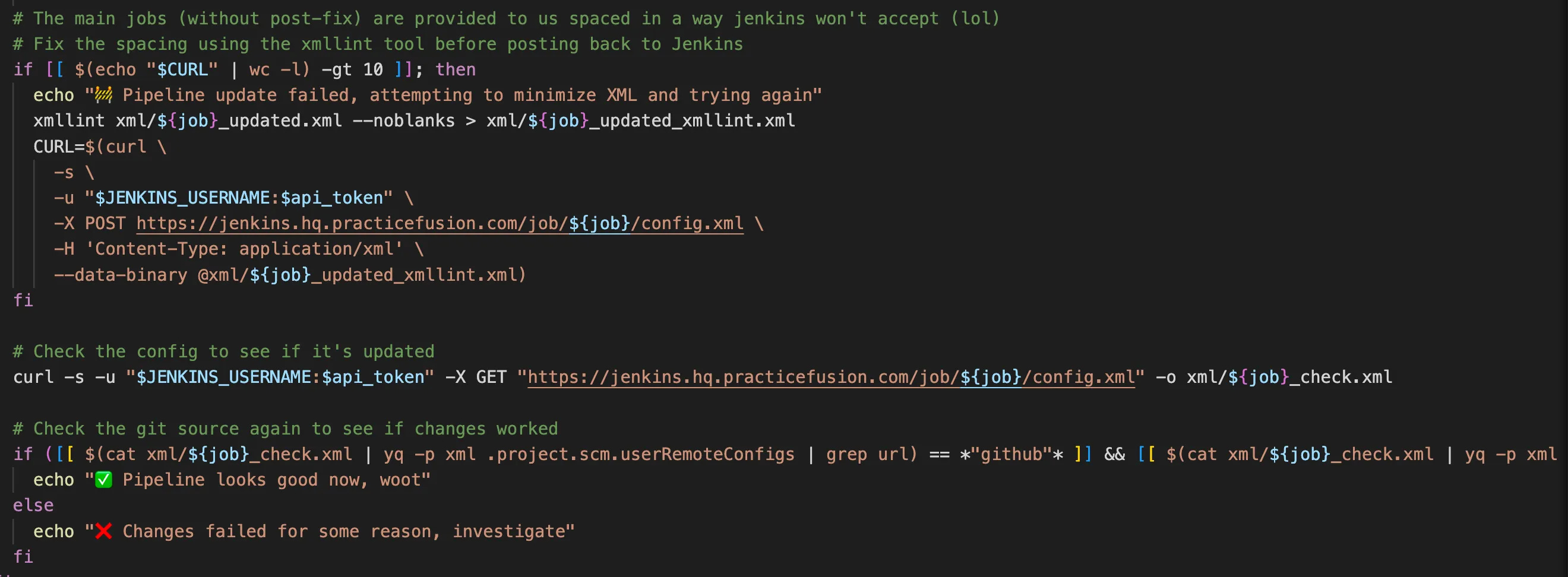
Our solution in the end was to iterate over Jenkins pipelines, download their config.xml file that contains all information, even that info used by pluggable modules, and use sed to create a new version of the config that points at the proper location, then post that file back.
| # Changes needed | |
| echo "🚧 Pipeline needs changes" | |
| # Modify the job with sed and write to new file | |
| cp xml/${job}_original.xml xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/scm/${PROJECT_SLUG_LOWERCASE}/${REPO_SLUG_LOWERCASE}.git</url>#<url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/scm/${PROJECT_KEY_UPPERCASE}/${REPO_SLUG_LOWERCASE}.git</url>#<url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/scm/${PROJECT_SLUG_LOWERCASE}/${REPO_SLUG_LOWERCASE}</url>#<url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/scm/${PROJECT_KEY_UPPERCASE}/${REPO_SLUG_LOWERCASE}</url>#<url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/scm/${PROJECT_SLUG_LOWERCASE}/${REPO_SLUG_LOWERCASE}</url>#<url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/scm/${PROJECT_KEY_UPPERCASE}/${REPO_SLUG_LOWERCASE}</url>#<url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s# <url>https://$STASH_URL/scm/${PROJECT_SLUG_LOWERCASE}/${REPO_SLUG_LOWERCASE}.git</url># <url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s# <url>https://$STASH_URL/scm/${PROJECT_KEY_UPPERCASE}/${REPO_SLUG_LOWERCASE}.git</url># <url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s# <url>https://$STASH_URL/scm/${PROJECT_SLUG_LOWERCASE}/${REPO_SLUG_LOWERCASE}</url># <url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s# <url>https://$STASH_URL/scm/${PROJECT_KEY_UPPERCASE}/${REPO_SLUG_LOWERCASE}</url># <url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s# <url>https://$STASH_URL/scm/${PROJECT_SLUG_LOWERCASE}/${REPO_SLUG_LOWERCASE}</url># <url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s# <url>https://$STASH_URL/scm/${PROJECT_KEY_UPPERCASE}/${REPO_SLUG_LOWERCASE}</url># <url>git@github.com:practicefusion/${JENKINS_JOB_SEARCH_STRING}.git\</url\>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/projects/${PROJECT_SLUG_LOWERCASE}/repos/${REPO_SLUG_LOWERCASE}</url>#<url>https://github.com/$GH_ORG/${JENKINS_JOB_SEARCH_STRING}</url>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/projects/${PROJECT_SLUG_LOWERCASE}/repos/${REPO_SLUG_LOWERCASE}/browse</url>#<url>https://github.com/$GH_ORG/${JENKINS_JOB_SEARCH_STRING}</url>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/projects/${PROJECT_KEY_UPPERCASE}/repos/${REPO_SLUG_LOWERCASE}</url>#<url>https://github.com/$GH_ORG/${JENKINS_JOB_SEARCH_STRING}</url>#g" xml/${job}_updated.xml | |
| sed -i '' "s#<url>https://$STASH_URL/projects/${PROJECT_KEY_UPPERCASE}/repos/${REPO_SLUG_LOWERCASE}/browse</url>#<url>https://github.com/$GH_ORG/${JENKINS_JOB_SEARCH_STRING}</url>#g" xml/${job}_updated.xml |
That solution worked well after lots of iterating — some config.xmls are stored with \n returns, and some are returned all as one line, and they apparently need to be posted back in the same way for no reason I understand. However, I eventually built out the logic to support it.
I’ve now updated more than 600 Jenkins pipelines and I’ll have updated more than 2k by the time this project ends.
Assign Repo Permissions
Now that repos are in GitHub, names normalized, and teams are created in GitHub, we need to link the two together. I have an existing tool I’ve built previously that runs each night from an Action, and massages all the github repos to our settings standards. Full write-up:
Let’s Do DevOps: Set GitHub Repo Permissions on Hundreds of Repos using GitHub’s Rest API using a…
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots…kymidd.medium.com
That tool was a perfect place to add code to link repos together. It’ll run each night, and if any new repos fit the existing naming patterns for ownership, permissions will be assigned based on the collection.
We check if the collection name is assigned. This isn’t populated by default since our script can’t derive collection based on a repo name or anything — rather, it’s populated in the CSV(-ish) file in this repo that sets flags for any deviations from normal for our repos. If it finds that info, we check the repo name, and same as the above tools, classify the ownership and assign permissions based on that classification.
Based on the classification, different teams are granted admin vs maintain vs not granted any rights at all.
| # If the repo's collection is populated, assign those permissions | |
| if [ ! -z "$COLLECTION_NAME" ]; then | |
| # Normalize capitalization of collection name into slug | |
| COLLECTION_SLUG=$(echo $COLLECTION_NAME | tr '[A-Z]' '[a-z]') | |
| GH_REPO_LOWERCASE=$(echo $GH_REPO | tr '[A-Z]' '[a-z]') | |
| # If Collection name is UI, grant UI team admin, granting merge rights | |
| if [[ "$COLLECTION_SLUG" == "ui" ]]; then | |
| echo "ℹ️ Repo classified as UI" | |
| # Admins | |
| rest_grant_repo_permissions TEAM_SLUG='uileads' PERMISSION='admin' | |
| # There are no other *Leads groups for UI collection | |
| # If data repo, promote data leads to admin, granting merge rights | |
| elif [[ "$GH_REPO" == *"database"* ]]; then | |
| echo "ℹ️ Repo classified as Database" | |
| # Admins | |
| rest_grant_repo_permissions TEAM_SLUG=$DATA_LEADS_TEAM_SLUG PERMISSION='admin' | |
| # Maintain | |
| rest_grant_repo_permissions TEAM_SLUG=$SERVICES_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| rest_grant_repo_permissions TEAM_SLUG=$TEST_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| rest_grant_repo_permissions TEAM_SLUG=$UI_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| # If test repo, promote test to admin, granting merge rights | |
| elif [[ "$GH_REPO" == *"test"* ]]; then | |
| echo "ℹ️ Repo classified as Test" | |
| #Admins | |
| rest_grant_repo_permissions TEAM_SLUG=$TEST_LEADS_TEAM_SLUG PERMISSION='admin' | |
| # Maintain | |
| rest_grant_repo_permissions TEAM_SLUG=$SERVICES_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| rest_grant_repo_permissions TEAM_SLUG=$UI_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| rest_grant_repo_permissions TEAM_SLUG=$DATA_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| # If collection name doesn't match others, classify as Platform | |
| else | |
| echo "ℹ️ Repo classified as Services (default classification)" | |
| # Admins | |
| rest_grant_repo_permissions TEAM_SLUG=$SERVICES_LEADS_TEAM_SLUG PERMISSION='admin' | |
| # Maintain | |
| rest_grant_repo_permissions TEAM_SLUG=$TEST_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| rest_grant_repo_permissions TEAM_SLUG=$UI_LEADS_TEAM_SLUG PERMISSION='admin' | |
| rest_grant_repo_permissions TEAM_SLUG=$DATA_LEADS_TEAM_SLUG PERMISSION='maintain' | |
| fi | |
| fi |
We run this tool nightly, and it’s assigned an unfathomable amount of permissions — likely more than 10k? Hard to count.
More
These are just the tools I remember writing! I’ve had to write many dozens of scripts to learn things from Stash, Jenkins, GitHub, and tie them all together in useful ways.
Summary
I absolutely ❤ large projects like this. The goal is clearly defined, and the means are left up to me. 10/10, would project again. These types of mandates permit a great deal of creativity and improvisation when building, something that I adore as an engineer.
An even greater challenge is to keep these tools organize and readable so others can use and run them when you’re away or after you’ve left your job. Write-ups (like this!) can help your team figure out what the heck you were doing with that code.
I hope the tools on this page help you see that even bash can be a useful language, that you don’t need 1 monolith tool that does it all, and that mapping two data sources together and taking action on it is absolutely a challenge and so fun.
Or something like that? Programming is cool.
Good luck out there.
kyler