
🔥Building a Teams Bot with AI Capabilities - Part 5 - GenAI Integration with Teams🔥
aka, what are all these GUIDs and why don't these APIs exist?

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
These articles are supported by readers, please consider subscribing to support me writing more of these articles <3 :)
This article is part of a series of articles, because 1 article would be absolutely massive.
Part 3: Delegated Permissions and Making Lambda Stateful for Oauth2
Part 4: Building the Receiver lambda to store tokens and state
Part 5 (this article): Finding messages, reading conversations in Teams
Hey all!
In the last article, we covered how the Receiver lambda gets an OAuth2 token that’s compatible with the GraphAPI, and how we encrypt and store that token so that our Worker lambda can utilize it to DO STUFF - like have AI conversations and post responses from our models back to the Teams platform.
Assuming that’s all working, each time our Worker is triggered now, we’re going to get a valid OAuth2 token, and some conversation information (someone tagged the bot, or messaged it directly), and it’s now our Worker lambda’s job to do the AI magic. There’s a few parts of AI magic we’ll cover.
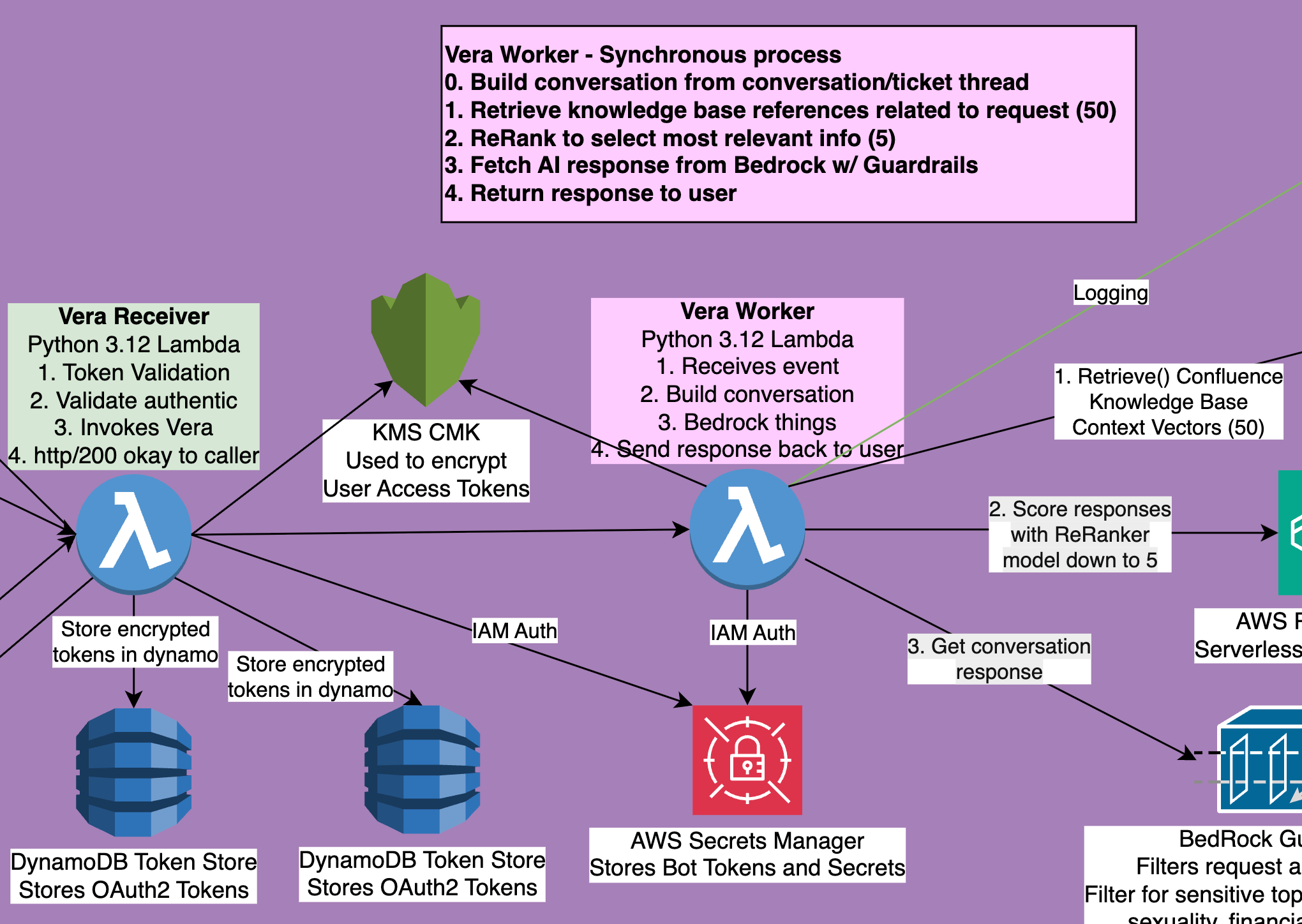
Extract the message context - is this a DM or tag in a Teams.. Team (We know naming stuff is hard $msft)
Read the previous messages if applicable
In a DM context, there’s no good way yet to differentiate different conversations, so we just respond directly to each question - there’s no follow-up/thread model. When Teams supports this (is that coming?) we could extend the bot to cover that model.
In a Teams Team context, read messages back. We have to limit this to some length, and not read ALL the messages if there’s hundreds. So we limit to like 20 messages.
Download any attachments to any message we read
This is hilariously very different on context because of how Teams doesn’t REALLY exist. If you share an attachment in a DM, it’s stored in your OneDrive. If you share an attachment in a Teams Team, it’s usually stored in that Team’s SharePoint storage. The names are sometimes transformed to be SharePoint/OneDrive compatible, which makes my pull my hair out. We’ll cover this really well lower on.
Read the user data of any post author
To detect pronouns, nicknames, etc.
Get an AI response
We’ve covered this well in previous articles (here’s the SlackBot articles), so we won’t cover this here
Post a response
Send our response back, properly formatted for Teams.
When it all works, it looks like this:
If you don’t want to walk through all this, the code we’re going to be talking about is here:
Bot Bearer Token Fetching
Lets first fetch the bot’s bearer token. That token is used to post responses to the user in 1:1 DM chats, and respond to a Team’s Team/Channel in shared context.
On line 4 we fetch the json-structured secrets package, and then load it on line 7. Lines 8 - 10, we assign particular values of the secrets to variables for easy use.
Then on line 13, we call get_teams_bearer_token and send most of our secret info to it. Lets follow that thread.
| def lambda_handler(event, context): | |
| #... | |
| # Fetch secret package | |
| secrets = get_secret_ssm_layer(bot_secret_name) | |
| # Disambiguate secrets | |
| secrets_json = json.loads(secrets) | |
| TENANT_ID = secrets_json["TENANT_ID"] | |
| CLIENT_ID = secrets_json["CLIENT_ID"] | |
| CLIENT_SECRET = secrets_json["CLIENT_SECRET"] | |
| # Get bearer token for the bot to use to post messages | |
| bot_bearer_token = get_teams_bearer_token(TENANT_ID, CLIENT_ID, CLIENT_SECRET) |
This function helps us get a token to use to post responses to the user when we’re ready to. We do this immediately so we can post error messages back if anything breaks.
On line 4, we set the token_url as a static string - this is required for all BotFramework compatible bot implementations.
Then on line 7 we assign the scope - the list of permissions we’re requesting. This bot only has the permissions required, so we don’t care if we get ALL of them.
Pro tip: If the bot is assigned broad/admin permissions, and you only want this bot to get limited permissions, you can prune permissions back here by what you request.
On line 10 we build our payload, and on line 18 we request the token.
On line 19, we raise an error if we get anything other than an http/200, and if we pass this check, on line 22, we extract the “access_token” from the response and return it on line 24. This helps validate that we are the bot, and we have a right to send responses AS the bot.
| def get_teams_bearer_token(TENANT_ID, CLIENT_ID, CLIENT_SECRET): | |
| # Token endpoint for Azure AD - multi tenant | |
| token_url = f"https://login.microsoftonline.com/botframework.com/oauth2/v2.0/token" | |
| # Bot Framework requires this scope | |
| scope = "https://api.botframework.com/.default" | |
| # Build the request | |
| payload = { | |
| "grant_type": "client_credentials", | |
| "client_id": CLIENT_ID, | |
| "client_secret": CLIENT_SECRET, | |
| "scope": scope, | |
| } | |
| # Request the token | |
| response = requests.post(token_url, data=payload) | |
| response.raise_for_status() # This will throw an error if the request fails | |
| # Extract the token | |
| bearer_token = response.json()["access_token"] | |
| return bearer_token |
Extracting the Auth Token
Before we do anything, we need the auth token so we can operate on behalf of the user. Remember, the “Receiver” lambda either had this cached or asked the user to go approve it through the SSO Card we sent. The Worker lambda (that does all this AI stuff) won’t be triggered until the auth token is valid and received.
Remember, we packed the auth token in the “event” that is passed from the Receiver (think Receptionist), as an encrypted, base64’d string.
Lets fetch the token blob on line 7 from the event payload, and then send it to the decrypt_user_auth_token() function on line 8. Lets follow that thread.
| def lambda_handler(event, context): | |
| #... | |
| # Get bearer token for the bot to use to post messages | |
| bot_bearer_token = get_teams_bearer_token(TENANT_ID, CLIENT_ID, CLIENT_SECRET) | |
| # Extract auth token from event | |
| user_graph_auth_token = event.get("token", "") | |
| user_graph_auth_token = decrypt_user_auth_token(user_graph_auth_token) |
The token is base64’d after being encrypted, so lets decode it on line 4.
Then we register a KMS client on line 7, and read the KMS CMK alias that we passed in from terraform as an environmental variable on line 10.
Then we pass the token (no longer encoded as base64, but still an encrypted blob) and the key alias to the kms.decrypt() function.
On line 19, we identify the plaintext response from the KMS call, and decode it as a utf-8 string.
PHEW, that was a lot to get the token. But it does very much help us not pass plaintext access tokens from users, and to not store them in dynamo unencrypted.
On line 22, we send the decrypted access token back.
| def decrypt_user_auth_token(encrypted_token): | |
| # Decode the base64 | |
| encrypted_token = base64.b64decode(encrypted_token) | |
| # Initialize KMS client | |
| kms = boto3.client('kms', region_name='us-east-1') | |
| # Read the CMK key alias from the environment variable | |
| cmk_key_alias = os.environ.get("CMK_ALIAS") | |
| # Decrypt the token | |
| response = kms.decrypt( | |
| KeyId=cmk_key_alias, | |
| CiphertextBlob=encrypted_token | |
| ) | |
| # Store accessToken in variable | |
| accessToken = response["Plaintext"].decode("utf-8") | |
| # Send the accessToken back | |
| return accessToken |
With that token passed back, lets head back to our main function.
Next up, we register the bedrock client, line 4, in the proper region. This is the client which lets us talk to bedrock for AI stuff.
Then we pass all the token and stuff to the message_handler() function in a try() block. If anything goes wrong in the bedrock AI call, we should be able to send the error right back to the user with lines 9 - 18.
Lets follow the message_handler() logic.
| def lambda_handler(event, context): | |
| #... | |
| # Build bedrock client | |
| bedrock_client = create_bedrock_client(model_region_name) | |
| # Build conversation, knowledge base, rerank, AI request, respond to Teams | |
| try: | |
| message_handler(event_body, bot_bearer_token, user_graph_auth_token, bedrock_client) | |
| except Exception as error: | |
| # If the request fails, print the error | |
| print(f"🚀 Error making request to Bedrock: {error}") | |
| # Return error as response | |
| respond_to_teams( | |
| bot_bearer_token, | |
| event_body, | |
| f"😔 Error making request to Bedrock: " + str(error), | |
| ) |
Following the Message Handler
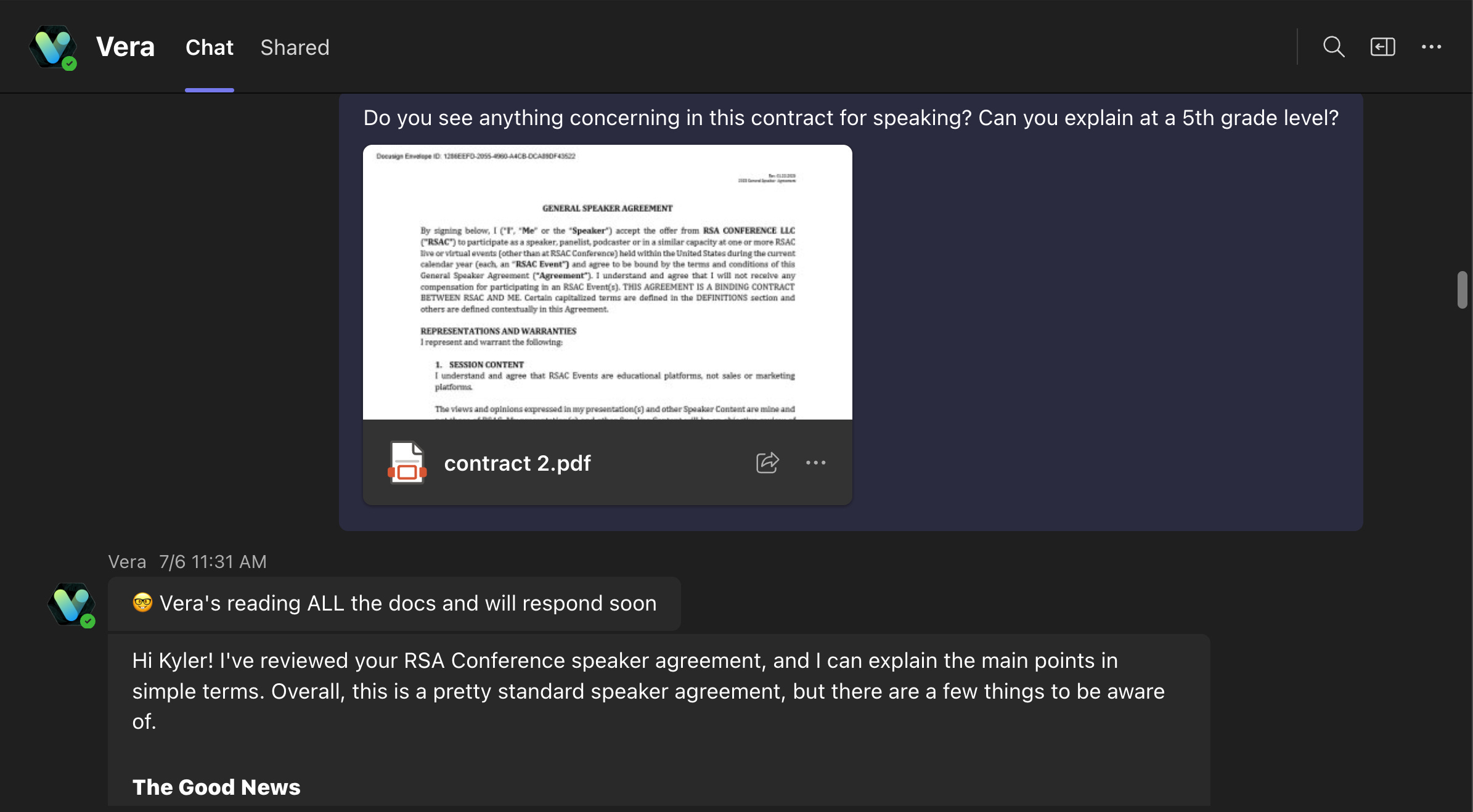
Now, the Teams response takes a bit longer than Slack does, something like 7-10 seconds. That’s a long time to wait for any response, you might think it’s broken! So I decided to build an immediate “working hard” message and I had fun with it.
From line 2-7 we created some messages, and then on line 12, we randomly pick one of those 4 and set it as the right-away response.
Then on line 15, we send the response to the user. It looks like this:

Let’s look closer at the respond_to_teams() function before we continue on.
| # "Loading" messages for Teams | |
| teams_loading_responses = [ | |
| "🤔 Vera is reading our knowledge bases and building a response", | |
| "🤓 Vera's reading ALL the docs and will respond soon", | |
| "🤖 Vera is reading everything and computing a response beep boop", | |
| "🤖 Vera's doing her best here, getting back to you shortly", | |
| ] | |
| def message_handler(event_body, bot_bearer_token, user_graph_auth_token, bedrock_client): | |
| # Randomly select a response | |
| response = random.choice(teams_loading_responses) | |
| # We're on it | |
| respond_to_teams( | |
| bot_bearer_token, | |
| event_body, | |
| response, | |
| ) |
The Arduous Journey of Building Conversation Context in Teams
There are a few ways to send responses to Teams - the BotKit has a few smooth ways, but I wanted to learn what I’m able, so I built it myself with the requests() library for pure http.
So we start with building the headers, line 4 of a Bearer token (remember the Bot token that authorizes us to send messages as the bot?).
Then we build the payload, which is the text response we’ll send, line 10-13.
Then we extract the serviceUrl (the URL we can POST a response to in order to respond, this comes in with the event_body), line 16, and the conversation ID, also in the event body, line 17.
Then we compile the URL we’ll post to, on line 21. Why do we have to construct a new URL to post a response, instead of just using the service_url that Teams sends us? I don’t know, maybe Teams engineers want to punish us ¯\_(ツ)_/¯
On line 20, we send the response.
| def respond_to_teams(bot_bearer_token, event_body, message): | |
| # Build auth headers | |
| headers = { | |
| "Authorization": f"Bearer {bot_bearer_token}", | |
| "Content-Type": "application/json", | |
| } | |
| # Create message payload | |
| payload = { | |
| "type": "message", | |
| "text": message, | |
| } | |
| # Find the service URL and conversation ID from the event body | |
| service_url = event_body["serviceUrl"] | |
| conversation_id = event_body["conversation"]["id"] | |
| # Send the message to Teams | |
| response = requests.post( | |
| f"{service_url}/v3/conversations/{conversation_id}/activities", | |
| headers=headers, | |
| json=payload | |
| ) |
Lets head back to the message_handler and continue unthreading stuff.
Our first stop is to build the “conversation” context. In a 1:1/DM context, we don’t do this at all, we’ll just return the question the user asks. However, in a Channel/Team chat, we walk back to the first message in the thread to build the response.
Lets follow the get_teams_conversation_history() function.
| def message_handler(event_body, bot_bearer_token, user_graph_auth_token, bedrock_client): | |
| # ... | |
| # Walk the previous messages to build conversation context | |
| # If personal chat, we only read most recent message, on history. Too hard to break out of context | |
| # For Teams channels, we read messages back in the channel/post/thread/whatever-they-called-it-now | |
| conversation = get_teams_conversation_history(user_graph_auth_token, event_body) |
This function is absurdly complex due to the different data structures and logic we need to follow to get this to work. It genuinely doesn’t seem like the back-end was constructed in a logical way for folks to utilize - maybe it was built by different teams over the years, or was intentionally made vague for security purposes? Regardless, there’s a lot going on, lets walk through it.
First, on line 2, we build the headers using the user’s graph auth token. That’s the token that lets us act like the user.
Then we populate some values that are provided to us. Rather than be actually useful, we use these breadcrumb trail items soon to look up the actually useful values. On line 7 and 8 we get the replyToId (only populated if user “reply”-ing to a message, and conversation_type.
If we’re in a Teams Team/Channel, it’ll be of type “channel”, and if it’s a 1:1/DM context, it’ll be a “personal”. Why “personal”? ¯\_(ツ)_/¯
We’ll assume the conversation_type this time is a Channel message. Now, we need to know the channel ID. In a sane world, this would be provided to us. We are not in a sane world. We’re instead provided a teamId (19:…@thread.tacv2), and we need a team_id (a GUID).
BIG SIGH
Now, you’d think there’s an API that helps us exchange this? HAH. Nope, we need to iterate through every Team the user is a part of, and see which ones match.
BIGGER SIGH
I wrote a function for this, resolve_team_id_from_team_id(), lets follow that thread.
| def get_teams_conversation_history(user_graph_auth_token, event_body): | |
| headers = { | |
| "Authorization": f"Bearer {user_graph_auth_token}" | |
| } | |
| # Populate the reply_to_id (if a reply) and conversation type | |
| reply_to_id = event_body.get("replyToId") | |
| conversation_type = event_body.get("conversation", {}).get("conversationType") | |
| # Look at type of conversation and build URL to fetch messages | |
| if conversation_type == "channel": | |
| # Need to exchange the teamId (19:...@thread.tacv2) for a graph API compatible team_id (a GUID) | |
| # Ugh, teams | |
| try: | |
| # Identify channelID (19:...@thread.tacv2) | |
| channel_id = event_body["channelData"]["channel"]["id"] | |
| # Exchange it for graph compatible team ID | |
| try: | |
| graph_compatible_ids = resolve_team_id_from_team_id(headers, channel_id) | |
| except Exception as error: | |
| print(f"🚫 Error resolving team ID from channel ID: {error}") | |
| raise error |
First of all, we look up all the Teams a user is joined to (SIGH), and then read all the teams in the json response. We fetch up to 100, which is probably not enough for some enterprises. If you have more, you’ll need to add pagination here, since we can only call 100 at a time.
On line 10, we iterate through each “team” json key to look up the team’s info, and then we need to get all the Channels in each Team (AGAIN, SIGH), line 14, and we iterate through those on line 22.
If the channel_id from the channel json matches the target_channel_id (the one we’re trying to identify from the message) matches, we know we’ve hit a winner. We return a json map of information.
I know this methodology is ridiculous. Maybe there exists an API that can do this rapidly, without iterating (but I couldn’t find it).
| def resolve_team_id_from_team_id(headers, target_channel_id): | |
| # Get all teams the user is a member of | |
| # Only supports up to 100 teams for now, should add pagination if needed at some point | |
| teams_response = requests.get( | |
| "https://graph.microsoft.com/v1.0/me/joinedTeams", headers=headers) | |
| teams_response.raise_for_status() | |
| teams = teams_response.json() | |
| # For each team, check each channel to find the one with the target_channel_id | |
| for team in teams.get("value", []): | |
| team_id = team["id"] | |
| team_name = team.get("displayName", "") | |
| channels_response = requests.get( | |
| f"https://graph.microsoft.com/v1.0/teams/{team_id}/channels", | |
| headers=headers | |
| ) | |
| channels_response.raise_for_status() | |
| channels = channels_response.json() | |
| # Iterate through channels to find the one with the target_channel_id | |
| for channel in channels.get("value", []): | |
| if channel["id"] == target_channel_id: | |
| channel_name = channel.get("displayName", "") | |
| return { | |
| "team_id": team_id, | |
| "channel_id": target_channel_id, | |
| "team_name": team_name, | |
| "channel_name": channel_name | |
| } |
Back to the get_teams_conversation_history() function, and we now have a valid graph-ID compatible Team and Channel ID. Now we need to read the conversation ID to identify the parent message.
This is interestingly (sadly) not called out as a separate attribute, it’s instead encoded as part of the (non-graph) conversation ID, which we extract on line 11.
| def get_teams_conversation_history(user_graph_auth_token, event_body): | |
| #... | |
| # Look at type of conversation and build URL to fetch messages | |
| if conversation_type == "channel": | |
| #... | |
| # Read conversation ID, find the parent message ID of the conversaton "Post"/thread | |
| try: | |
| full_convo_id = event_body.get("conversation", {}).get("id", "") | |
| parent_message_id = None | |
| if ";messageid=" in full_convo_id: | |
| parent_message_id = full_convo_id.split(";messageid=")[-1] | |
| else: | |
| raise Exception("❓ Could not extract root message ID from conversation ID") | |
| except Exception as error: | |
| print(f"🚫 Error extracting root message ID: {error}") | |
| raise |
Now that we know the parent message ID, we can get all the replies to that message via graph, line 6.
We encode it as json, line 12, and extract the messages values on line 13.
The messages are encoded in newest first, which is odd to me (?). Slack encodes replies in order, chronologically, Teams encodes them as newest first. That’s easy to fix with python though, we just reverse them, line 16.
| def get_teams_conversation_history(user_graph_auth_token, event_body): | |
| #... | |
| if conversation_type == "channel": | |
| #... | |
| # Fetch all responses in the Post/thread | |
| url = f"https://graph.microsoft.com/v1.0/teams/{team_id}/channels/{channel_id}/messages/{parent_message_id}/replies" | |
| # Get previous messages | |
| response = requests.get(url, headers=headers) | |
| if response.status_code != 200: | |
| raise Exception(f"Graph API error {response.status_code}: {response.text}") | |
| data = response.json() | |
| messages = data.get("value", []) | |
| # Sort so we get the oldest first | |
| messages = list(reversed(messages)) |
Now we have a structured json list of messages, but if you’ve been reading carefully you’ll notice the API Teams provides only lets us read all the “replies” to a parent message, not that parent message itself. So we have all messages in the thread EXCEPT the parent message, which is pretty funny in my opinion.
It’s easy enough to sort out though - we identify the root/parent message ID, line 11, then structure a graph call to get the individual message, line 14-16, then structure it as json, line 17.
Since the messages list is in chronological order, we want to insert the root message in the FIRST position, so we prepend the message on line 20.
| def get_teams_conversation_history(user_graph_auth_token, event_body): | |
| #... | |
| if conversation_type == "channel": | |
| #... | |
| ### The very first message in the thread has 1 parent, which is skipped. Need to fetch it separately | |
| # Get the replyToId from the first message in the thread | |
| if not messages or "replyToId" not in messages[0]: | |
| print("❓ No replyToId found in thread, can't fetch root post.") | |
| else: | |
| # Fetch the root message (the original Post) | |
| root_id = messages[0]["replyToId"] | |
| # Fetch the root message (the original Post) | |
| url = f"https://graph.microsoft.com/v1.0/teams/{team_id}/channels/{channel_id}/messages/{root_id}" | |
| resp = requests.get(url, headers=headers) | |
| resp.raise_for_status() | |
| root_post = resp.json() | |
| # Prepend it to the list | |
| messages = [root_post] + messages |
If the conversation type is personal, we’re in a 1:1/DM context. We can still read back messages, but there is no “root” message since threads don’t (currently) exist in the DM context in Teams.
We do all the same stuff, we just read back a static number of messages in the 1:1 chat (in the case of my code, the default is 21 messages back).
| def get_teams_conversation_history(user_graph_auth_token, event_body): | |
| #... | |
| if conversation_type == "channel": | |
| # ... | |
| elif conversation_type == "personal": | |
| user_aad_id = event_body["from"]["aadObjectId"] | |
| # If replying to message | |
| if reply_to_id: | |
| chat_id = event_body["conversation"]["id"] | |
| else: | |
| # Find graph API compatible chat_id from conversation_id (Teams APIs are weird) | |
| chat_id = resolve_chat_id_from_installed_apps(user_graph_auth_token, user_aad_id) | |
| # Read back the most recent messages in the personal chat | |
| url = f"https://graph.microsoft.com/v1.0/chats/{chat_id}/messages?$top={teams_dm_conversation_read_msg_count}" | |
| # Get previous messages | |
| response = requests.get(url, headers=headers) | |
| if response.status_code != 200: | |
| raise Exception(f"Graph API error {response.status_code}: {response.text}") | |
| data = response.json() | |
| messages = data.get("value", []) | |
| # Sort so we get the oldest first | |
| messages = list(reversed(messages)) |
Cleaning the Messages of Junk
Of course, many of those messages are junk - the SSO Auth card, for example, or the “working hard” messages we send to let the users know we’re working on things.
We need to filter those messages out for this conversation to make more sense, and to get better results from our knowledge base dip. So we call a function to do so, called message_messages(), on line 10, and send all our messages to it.
Lets zoom in.
| def get_teams_conversation_history(user_graph_auth_token, event_body): | |
| #... | |
| if conversation_type == "channel": | |
| #... | |
| elif conversation_type == "personal": | |
| #... | |
| # Filter messages | |
| # This excludes the bot's loading messages, the authentication card, and any messages which are invalid or blank | |
| messages = massage_messages(messages, conversation_type) |
First of all, we read all the messages, and remove all the ones that contain the “loading” messages we send, line 3-6.
Then we read the messages for any SSO/auth Cards we’ve sent, lines 9-15.
Then we read for this odd message type, unknownFutureValue. This is a special value in Teams to indicate a future message type that our client doesn’t support. No idea what it means, but I’ve only seen it as junk and never containing anything useful, so we skip em.
Then on line 23, we filter for just the most recent message from the user. This is a necessary workaround to keep threads focused on a single topic. I’m hoping in the future “Channels”/”Threads” will come to the DM/1:1 context of Teams, and we can always read back threads, rather than trying to guess at separate topical boundaries in these chats.
Now cleaned, we return the messages.
| def massage_messages(messages, conversation_type): | |
| # Exclude the bot messages that contain any of the teams_loading_responses substrings | |
| messages = [ | |
| msg for msg in messages | |
| if not any(resp in msg.get("body", {}).get("content", "") for resp in teams_loading_responses) | |
| ] | |
| # Exclude any messages that are cards, can tell if attachment[0].contentType is "application/vnd.microsoft.card.adaptive" | |
| # The authentication card is a card, and doesn't include meaningful information | |
| messages = [ | |
| msg for msg in messages | |
| if not ( | |
| msg.get("attachments") and | |
| msg["attachments"] and | |
| msg["attachments"][0].get("contentType") == "application/vnd.microsoft.card.adaptive" | |
| ) | |
| ] | |
| # Exclude messages that are "messageType": "unknownFutureValue", | |
| messages = [ | |
| msg for msg in messages | |
| if msg.get("messageType") != "unknownFutureValue" | |
| ] | |
| # If in 1:1 chat, we only want the most recent message from the user | |
| if conversation_type == "personal" and len(messages) > 1: | |
| # Get the most recent message from the user | |
| messages = [messages[-1]] | |
| # Return | |
| return messages |
Summary
I want to finish this out, but this article is getting HUGE, so lets call it here. In this article we covered how we can use a user’s auth token to read historical messages and their metadata from either a DM or Teams/Channel context.
In the next article we’ll talk about how we fetch attachments (it’s way more complex than you think it’ll be) and look up user’s information to build the whole conversation, then to post the response.
Good luck out there!
kyler